AWS Iot Coreのルールエンジンで Protocol Buffers を直接デコードするという少々マニアックな話です。
以下のAWS公式ブログでも紹介されている内容です。
本機能は2022/12 に追加されています。 aws.amazon.com
目次
背景
Protocol Buffers(Protobuf) について
以下の記事が非常にわかりやすいです。
あらかじめスキーマ(.proto)を作成しておき、それをメッセージをシリアライズ/デシリアライズしてAP間の通信に利用します。
バイナリ形式となるため、データが小さくなる、高速に処理できるなどのメリットがあります。
以下Chat GPTさんにメリットを解説してもらいました。
Protocol Buffersのシリアライズに関する特徴とメリットを以下に示します。
効率性: Protocol Buffersはバイナリ形式でデータをシリアライズするため、テキストベースの形式(例: JSONやXML)よりもデータサイズが小さくなります。これにより、通信やストレージにおいて帯域幅や容量を節約し、パフォーマンスを向上させることができます。
高速性: バイナリ形式のシリアライズは、テキスト形式よりも高速に処理されます。そのため、Protocol Buffersはデータのエンコードとデコードが高速に行われるため、リアルタイム性や応答速度が要求されるアプリケーションに適しています。
拡張性とバージョン管理: Protocol Buffersはデータ構造を定義する.protoファイルを使用しており、このファイルを編集することでデータ構造を簡単に変更できます。また、古いバージョンと互換性を保ちながら新しいフィールドやメッセージを追加することも可能です。
言語間の相互運用性: Protocol Buffersは複数のプログラミング言語でサポートされており、同じ.protoファイルを使用して異なる言語間でデータを交換することができます。このため、異なるプラットフォームやサービス間での相互運用性が向上します。
データの構造化とタイプセーフ: Protocol Buffersは、データ構造を事前に定義するため、コンパイル時にタイプチェックが行われます。そのため、データの構造が明確になり、プログラム内でのデータの取り扱いが安全になります。
上記のため、マイクロサービス間の通信(gRPC)や、IoTにおけるIoTデバイス〜サーバー間通信などでよく使われます。
今回は IoT における通信(要はMQTT)を題材とします。具体的にはAWS IoT Coreを介してIoTデバイスとサーバー(Consumer)が通信するケースを考えます。

Protobufのメッセージはバイナリ形式なので、受信側でデシリアライズ(デコード)をする必要があります。 上記の図のようにAPで直接デシリアライズしても良いのですが、よりクラウドネイティブな方法も考えたいところです。
IoT Core からデシリアライズ用のLambda関数を呼び出す
第2のアプローチとして、デシリアライズ用のLambda関数をIoT Coreから呼び出す方法があります。Protobufのメッセージを受信時に、IoT Coreのルールエンジンからあらかじめ実装しておいたデシリアライズ用のLambda関数を呼び出し、デシリアライズしたメッセージをConsumerに流す方式です。

これは以下の記事でも試していました。
この方式だとConsumerはデシリアライズされたメッセージ(JSON)を受け取ることから処理がしやすい、デシリアライズのロジックをConsumer側で持たなくて良いというメリットがあります。
前回の記事ではデシリアライズしたメッセージを Kinesis Data Streams -> Lambda と流して処理するようなアーキテクチャを組んでいました。
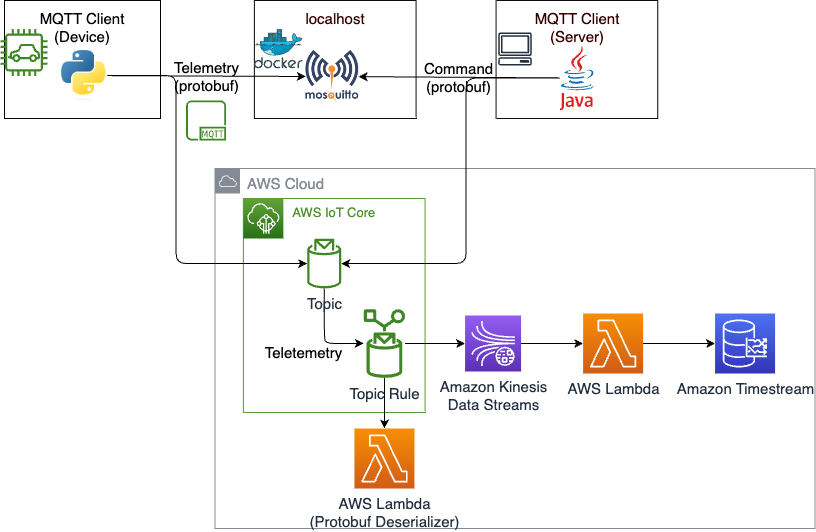
これでも良いのですが、デシリアライズ用のLambdaを実装する手間がかかります。レイヤーの作成など一工夫が必要でやや面倒です。
IoT Coreで直接デシリアライズを行う
第3のアプローチが、今回の主題であるIoT Coreで直接デシリアライズする方法です。
S3バケットにあらかじめ Protobuf のデシリアライズに必要なファイル(ディスクリプタ)を配置しておき、IoT Core Ruleが直接 Protobuf をデシリアライズする方式です。
この方式だと、Protobuf のデシリアライズをマネージドな仕組みで実現できるため、さらに管理コストが下がります。またスキーマが変わった際もS3バケットのオブジェクトを差し替えるだけなので簡単に変更できるというメリットもあります。

今回はこちらを実装してみます
実装について
前回の記事で作成したアーキテクチャにおいて、Protobufのデシリアライズ箇所を差し替えていきます。
アーキテクチャとしては以下になります。左上のIoTデバイスを模したプログラムからテレメトリーをProtobufで送信し、IoT Core でデシリアライズし Kinesis Data Streams -> Lambda と流して最後はTimestreamに格納します。
前回から大きく変更する点は赤枠の部分です。

実装は以下にあります。例の如くCDKをメインで使っています。
また設定手順としては以下の開発者ガイドが参考になります。
Protobuf と ディスクリプタの用意
今回は以下のような Protobuf のスキーマを使用します(プロジェクトのap/proto/dummy_telemetry.proto)。id、緯度経度、タイムスタンプのみを持つシンプルなものです。
syntax = "proto3"; option java_package = "com.example"; option java_outer_classname = "DummyTelemetryProto"; import "google/protobuf/timestamp.proto"; message DummyTelemetry { string id = 1; double latitude = 2; double longitude = 3; google.protobuf.Timestamp timestamp = 4; }
こちらを元にIoT Core Ruleが使用するディスクリプタを生成します。以下のようにディスクリプタのファイル名と、生成元の .proto を指定します。
別の .proto をインポートしている場合はそれらも指定する必要があります(詳細は開発者ガイドをご参照ください)
protoc --include_imports -o filedescriptor.desc dummy_telemetry.proto
ここで生成したディスクリプタ(filedescriptor.desc)を使用します。
ディスクリプタを使用してデシリアライズするように設定
まずはディスクリプタをS3バケットに配置します。今回はプロジェクト上にディスクリプタを配置しておき、CDKの aws_s3_deployment を使用して、cdk deploy時にバケットに配置されるようにしています。
// S3 Bucketを作成 const fileDescriptorBucket = new s3.Bucket(this, 'FileDescriptorBucket', { autoDeleteObjects: true, removalPolicy: cdk.RemovalPolicy.DESTROY, eventBridgeEnabled: true, }) // ディスクリプタをS3バケットに配置 new s3deploy.BucketDeployment(this, 'FileDescriptorDeploy', { sources: [s3deploy.Source.asset("filedescriptor/")], destinationBucket: fileDescriptorBucket, destinationKeyPrefix: "msg/" })
またバケットポリシーを設定して、IoT Coreからディスクリプタにアクセスできるようにします。
// バケットポリシーを設定 fileDescriptorBucket.addToResourcePolicy( new iam.PolicyStatement({ effect: iam.Effect.ALLOW, actions: ['s3:Get*'], resources: [ `${fileDescriptorBucket.bucketArn}/*`, `${fileDescriptorBucket.bucketArn}`], principals: [new iam.ServicePrincipal('iot.amazonaws.com')] }) )
その上で IoT Core Rule のSQLでディスクリプタを参照して、デシリアライズするように設定します。
new iot.TopicRule(this, 'TopicRule', { topicRuleName: 'MqttTopicRule', sql: iot.IotSql.fromStringAsVer20160323(`SELECT VALUE decode(*, 'proto', '${fileDescriptorBucket.bucketName}', 'msg/filedescriptor.desc', 'dummy_telemetry', 'DummyTelemetry') FROM 'python/messages/#'`), // ★ここ actions: [ new actions.KinesisPutRecordAction(stream, { partitionKey: '${newuuid()}', }) ], errorAction: new actions.CloudWatchLogsAction(logGroup) });
若干わかりづらいのでSQLの部分だけ抜粋します。decodeの部分が肝です。開発者ドキュメントも合わせてご参照ください。
SELECT VALUE decode( *, -- デシリアライズするprotobufのメッセージを指定。* でバイナリペイロードを直接渡せる。 'proto', -- 固定値 '${fileDescriptorBucket.bucketName}', -- ディスクリプタを置いたバケット名を指定(例の場合はcdk deploy時に実際のバケット名に置き換わる) 'msg/filedescriptor.desc', -- ディスクリプタのS3バケット上のキーを指定 'dummy_telemetry', -- .proto のファイル名を指定(例の場合は dummy_telemetry.protを使用) 'DummyTelemetry' -- .proto 内に定義した構造体の名称を記載 ) FROM 'python/messages/#' -- サブスクライブするMQTTのトピックを指定
設定としてはこれだけです。
動かしてみる
では実際に動作させてみます。cdk deployでAWSリソース構築後に、IoTデバイスを模したプログラムをローカルPC等で動作させ、IoT Coreに対して Protobuf を送信します。
以下のように適当な値を設定した Protobuf のメッセージを生成(シリアライズ)した上で、MQTTトピックに発行します。
from google.protobuf.timestamp_pb2 import Timestamp from proto.dummy_telemetry_pb2 import DummyTelemetry def create_message(client_name="dummy"): # ダミーテレメトリオブジェクトを作成 dummy_telemetry = DummyTelemetry() # idおよび緯度経度を設定 dummy_telemetry.id = client_name dummy_telemetry.latitude = 35.681236 dummy_telemetry.longitude = 139.767125 # 現在時刻JSTを設定 JST = timezone(timedelta(hours=+9), 'JST') now = datetime.now(JST) timestamp = Timestamp() timestamp.FromDatetime(now) dummy_telemetry.timestamp.CopyFrom(timestamp) # メッセージのシリアライズ serialized_message = dummy_telemetry.SerializeToString() return serialized_message
実際にProtobufをデシリアライズできているか、赤枠のLambdaのログで確認してみます。

event のログの抜粋は以下です。問題なくデシリアライズできています。
{'id': 'hoge', 'latitude': 35.681236, 'longitude': 139.767125, 'timestamp': '2024-03-16T04:58:32.932980Z'}
なお、本筋とは少しずれますが 前回のLambdaによるデシリアライズから、今回のIoT Core Ruleへのデシリアライズに変えたことで、時刻(timestamp)の形式が変わりTimestreamへの書き込み時にエラーとなりました。
○発生したエラー
An error occurred (ValidationException) when calling the WriteRecords operation: Invalid time for record.
○Lambdaに連携されるevent(Protobufをでシリアライズしたもの)
# 前回(時刻がUNIXエポック) {'payload': {'id': 'hoge', 'latitude': 35.681236, 'longitude': 139.767125, 'timestamp': 1710566057940}} # 今回(時刻が ISO 8601) {'id': 'hoge', 'latitude': 35.681236, 'longitude': 139.767125, 'timestamp': '2024-03-16T04:58:32.932980Z'}
上記のため timestamp -> UNIXエポック に変換してから、Timestreamに書き込むようLambdaの実装を変更しています。
from datetime import datetime # ISO 8601 -> UNIX エポックに変換 def timestamp_to_epoch(timestamp): dt = datetime.fromisoformat(timestamp.replace("Z", "+00:00")) return int(dt.timestamp() * 1000) # -----中略----- # マルチメジャーレコードのデータポイントの作成 data_point = { "Time": str(timestamp_to_epoch(payload["timestamp"])), # ISO 8601->UNIXエポックに変換してから設定するように変更 "TimeUnit": "MILLISECONDS", "MeasureName": "device_metrics", "MeasureValueType": "MULTI", "MeasureValues": records, "Dimensions": dimensions, } print(data_point) # データポイントを書き込む try: response = timestream_client.write_records( DatabaseName="TelemetryDatabase", TableName="TelemetryTable", Records=[data_point], ) print(response)
まとめ
.protoから生成するディスクリプタをS3バケットに配置しておくことで、IoT Core Rule で直接 Protobuf メッセージをデシリアライズして後続に流すことが可能です。
マネージドな仕組みで実現可能なので IoT × Protobuf を行う場合は選択肢の一つとして考えておきたいです。