AWS Glueを使用してRDS内のデータのETLを行う機会があったので、CDKで実装してみました。いくつかハマった点もあったのでその記録です。
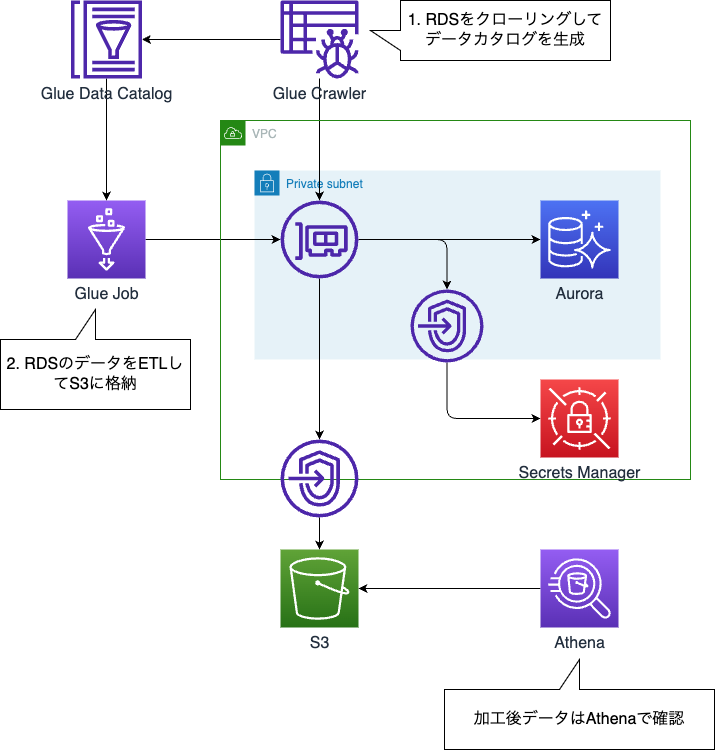
今回は以下のようにRDSにアクセスするCrawlerとジョブを実装します
- Glue Crawler からRDSにアクセスしてData Catalogを生成
- Glue JobからRDSのデータをETLしてS3に格納。
目次
実装について
以下のWorkshopでGlueからRDSにアクセスする題材があったので、こちらを流用しました。
catalog.us-east-1.prod.workshops.aws
実装したものは以下にあります(今回の記事の内容以外のものも含まれています)。 github.com
実装詳細
今回はCDKで実装していきます。
なお記事執筆時点ではAWS Glueの正式なL2 Constructは存在しません。そのためαモジュールの @aws-cdk/aws-glue-alpha を使用して実装していきます。
VPCやAuroraを実装
VPCやAuroraなどGlue以外のリソースを実装してきます。
VPCは今回NAT GW無しにしています。
RDSについてネタ元のWorkshopではAurora MySQLを使用していましたが、今回 RDS Data APIを使ってみたかった(詳細後述)のため、PostgreSQLに変えています。
また記事執筆時点ではAurora PostgreSQL14以降を使用すると、そのままではGlueから接続できずにエラーになります。そのため今回は一旦13を使用します。
※参考
// vpc const vpc = new ec2.Vpc(this, 'Vpc', { natGateways: 0, // 0を指定 maxAzs: 2, subnetConfiguration: [ { name: 'private-subnet-', subnetType: ec2.SubnetType.PRIVATE_WITH_EGRESS, cidrMask: 24 }, { name: 'public-subnet-', subnetType: ec2.SubnetType.PUBLIC, cidrMask: 24 } ] }) // Aurora const auroraCluster = new rds.DatabaseCluster(this, 'DatabaseInstance', { engine: rds.DatabaseClusterEngine.auroraPostgres({ version: rds.AuroraPostgresEngineVersion.VER_13_13 }), // 13を指定 vpc: vpc, vpcSubnets: vpc.selectSubnets({ subnetType: ec2.SubnetType.PRIVATE_WITH_EGRESS }), writer: rds.ClusterInstance.serverlessV2('Writer', {}), serverlessV2MinCapacity: 0.5, serverlessV2MaxCapacity: 1, credentials: { username: 'glueworkshop' }, backup: { retention: cdk.Duration.days(1) }, defaultDatabaseName: 'glueworkshop', removalPolicy: cdk.RemovalPolicy.DESTROY, enableDataApi: true // Data APIを有効化 })
またVPCエンドポイントを追加します。
- Secrets Manager:GlueからRDSにアクセスする際、認証情報取得のために必要。
- S3:ETL後のデータを書き込むため必要。
vpc.addInterfaceEndpoint('SecretsManagerVpcEndpoint', { service: ec2.InterfaceVpcEndpointAwsService.SECRETS_MANAGER }) vpc.addGatewayEndpoint('GlueGatewayEndpoint', { service: ec2.GatewayVpcEndpointAwsService.S3 })
Glue Connection周りの実装
GlueからVPC内リソースにアクセスするときは、ENIが生えてきてアクセスする形になります。なお実際はENIは複数生えてくるため、IPが枯渇しないように注意が必要です。
そのためのセキュリティグループやGlue Connectionの設定を行います。
まずはセキュリティグループを作成します。自己参照ルールが必要なのがポイントです。
※参考
またv.2.138.0でec2.PortにおいてWell-known portをenumで実装できるようになりました。今回の実装例ではPOSTGRES(ポート5432)を使用しています。
// セキュリティグループを作成 const glueSecurityGroup = new ec2.SecurityGroup(this, 'GlueSG', { vpc: vpc, }) // 自己参照ルールを追加 glueSecurityGroup.connections.allowInternally(ec2.Port.allTcp()) // RDSにアクセスできるよう設定 glueSecurityGroup.connections.allowTo(auroraCluster, ec2.Port.POSTGRES)
次にDB接続時などに必要に成るGlue Connectionを作成していきます。なお内部動作としては以下の記事が参考になりました。
今回マルチAZ構成ですが、Glue Connectionはサブネットごとに作る必要があるため、mapでリストにしています。
またDBへの接続情報はConnection APIを使用して定義しています。Secrets ManagerをID指定で設定できるなど非常に便利です。
const glueConnections = vpc.privateSubnets.map((subnet, index) => new glue.Connection(this, `GlueConnection-${index}`, { type: glue.ConnectionType.JDBC, securityGroups: [glueSecurityGroup], subnet: subnet, properties: { JDBC_CONNECTION_URL: `jdbc:postgresql://${auroraCluster.clusterEndpoint.socketAddress}/glueworkshop`, JDBC_ENFORCE_SSL: 'false', SECRET_ID: auroraCluster.secret!.secretName // Secrets ManagerのID(名称)を指定 } }) )
Crawlerの実装
次にCrawler関連のリソースを実装してきます。
まずはGlueで使用するロールや、Glueデータベースを作成していきます。
// ロール作成 const glueRole = new iam.Role(this, 'RdsGlueRole', { assumedBy: new iam.ServicePrincipal('glue.amazonaws.com') }); glueRole.addManagedPolicy( iam.ManagedPolicy.fromAwsManagedPolicyName('service-role/AWSGlueServiceRole')); // Secrets Managerの読み取り権限を付与 auroraCluster.secret!.grantRead(glueRole) // Glueデータベースを作成 const database = new glue.Database(this, 'RdsDatabase', { databaseName: 'rds-database' })
そしてCrawlerを実装していきます。Cralwerはalpha moduleに含まれていないので、L1 ConstructのCfnClawlerを使用しています。
今回マルチAZ構成のためGlue Connectionも複数作成してリストとしていましたが、Crawlerにおいて異なるサブネットのGlue Connectionを指定することはできません。
One crawler cannot contain targets with different VPC Subnet's
そのためリストの中から一つだけ指定する形にしています。ということは単一のCrawlerにおけるConnectionをマルチAZ構成にして耐障害性を高めることはできないということなんですね...(違ったらどなたか教えてください)。
const crawler = new CfnCrawler(this, 'RdsCraweler', { role: glueRole.roleArn, name: 'rds_crawler', targets: { jdbcTargets: [ { connectionName: glueConnections[0].connectionName, path: 'glueworkshop/%' } ] }, databaseName: database.databaseName, tablePrefix: 'rds_' })
Glue Jobの実装
最後にGlue Jobを実装していきます。
const rdsJob = new glue.Job(this, 'RdsJob', { executable: glue.JobExecutable.pythonEtl({ glueVersion: glue.GlueVersion.V4_0, pythonVersion: glue.PythonVersion.THREE, script: glue.Code.fromAsset('src/rds.py') }), // Spark UIの有効化 sparkUI: { enabled: true, bucket: sparkUiBucket }, enableProfilingMetrics: true, role: glueRole, workerType: glue.WorkerType.G_1X, workerCount: 4, // Flexジョブの指定 executionClass: glue.ExecutionClass.FLEX, defaultArguments: { '--s3_bucket': `s3://${rdsJobBucket.bucketName}/`, '--region_name': cdk.Stack.of(scope).region, '--TempDir': `s3://${rdsJobBucket.bucketName}/output/temp`, '--TargetDir': `s3://${rdsJobBucket.bucketName}/output/orders`, '--job-bookmark-option': 'job-bookmark-enable' // Job Bookmark有効化 }, connections: glueConnections // 複数Connectionを指定 }) // S3バケットの操作権限を付与 rdsJobBucket.grantReadWrite(rdsJob)
今回ポイントとして、Glue Connectionを複数渡しています(マルチAZ構成)。このようなケースでは通常は最初のConnectionが使われますが、最初のConnectionがAZ障害等で使用できない場合は次のConnectionが使用されます。これによりGlue JobをマルチAZ構成にすることができます。
If multiple connections with different subnets are attached, the subnet settings from the first connection will be used by default. However, if the first connection is unhealthy for any reason – for instance, if the availability zone is down then the next connection is used. ( Serverless ETL and Analytics with AWS Glue: Your comprehensive reference guide to learning about AWS Glue and its features, p.25より引用 )
※以下の書籍から引用。AWSの中の人による書籍であり、Glueの詳細を学べるため深く理解したい人は必読です。
")
また、その他にSpark UIの設定、Flexジョブの仕様、ジョブブックマークなど検証したかったものをいくつか設定していますが、必須のものではありません。
なおジョブブックマークですが、RDBがインプットの場合は新規に生成されたレコードのみが処理対象となるため注意が必要です。更新されたレコードは処理されずに、スキップされます。
Job bookmarks work for new rows, but not for updated rows.
Glue Jobのスクリプトは以下です(Wokrshopのものほぼそのまま)。AuororaのデータをETLし、S3にJSONと出力+データカタログへの書き込みを行っているのみです。
# 必要なモジュールをインポート import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job from awsglue.dynamicframe import DynamicFrame # ジョブ実行時の引数を取得 args = getResolvedOptions(sys.argv, ["JOB_NAME", "TargetDir", "TempDir"]) # SparkContextとGlueContextを初期化 sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session # Glueジョブを作成し、初期化 job = Job(glueContext) job.init(args["JOB_NAME"], args) # ターゲットディレクトリのパスを取得 tgt_path = args["TargetDir"] # PostgreSQLテーブルをDynamicFrameとして読み込み SQLtable_node1 = glueContext.create_dynamic_frame.from_catalog( database="rds-database", table_name="rds_glueworkshop_public_orders", additional_options={ "hashexpression": "orderid", "hashpartitions": 10, }, transformation_ctx="SQLtable_node1", ) # SQLtable_node1にレコードが存在する場合 if SQLtable_node1.count() > 0: # DynamicFrameをDataFrameに変換 postdf = SQLtable_node1.toDF() # DataFrameをシャッフルし、パーティションを1つにまとめる postdf = postdf.coalesce(1) # 処理レコード数とorderidの最大/最小値を出力 print("Processed Records in this Batch- ", postdf.count()) print("ID of records processed in this Batch- ") postdf.agg({"orderid": "max"}).show() postdf.agg({"orderid": "min"}).show() # DataFrameをDynamicFrameに変換 postdyf = DynamicFrame.fromDF(postdf, glueContext, "postdyf") # S3への出力先を設定 S3bucket_node3 = glueContext.getSink( path=tgt_path, connection_type="s3", updateBehavior="UPDATE_IN_DATABASE", partitionKeys=[], enableUpdateCatalog=True, transformation_ctx="S3bucket_node3", ) # 出力後のデータカタログ情報を設定 S3bucket_node3.setCatalogInfo( catalogDatabase="rds-database", catalogTableName="orders_target" ) # 出力データ形式をJSONに設定 S3bucket_node3.setFormat("json") # DynamicFrameをS3に書き込み S3bucket_node3.writeFrame(postdyf) # SQLtable_node1にレコードが存在しない場合 else: print("Processed Records in this Batch- 0") # ジョブを確定 job.commit()
CLIでの実行時に必要な値をOutput
RDS Data APIやGlue Crawler / Job実行時に必要な値をCLIで取得できるよう、Outputしておきます。
// Output new cdk.CfnOutput(this, 'AuroraArn', { value: auroraCluster.clusterArn, key: 'AuroraArn' }) new cdk.CfnOutput(this, 'SecretArn', { value: auroraCluster.secret!.secretArn, key: 'SecretArn' }) new cdk.CfnOutput(this, 'GlueCrawlerName', { value: crawler.name!, key: 'GlueCrawlerName' }) new cdk.CfnOutput(this, 'GlueJobName', { value: rdsJob.jobName, key: 'GlueJobName' })
動作確認
データの準備
今回はRDS Data APIを使用して、CLIでテーブル作成およびデータのINSERTを行ってみました。
# AuroraおよびSecrets ManagerのARN取得 AURORA_ARN=$(aws cloudformation describe-stacks --stack-name WorkshopServerlessDatalakeStack --output text --query 'Stacks[0].Outputs[?OutputKey == `AuroraArn`].OutputValue') SECRET_ARN=$(aws cloudformation describe-stacks --stack-name WorkshopServerlessDatalakeStack --output text --query 'Stacks[0].Outputs[?OutputKey == `SecretArn`].OutputValue') # テーブル作成 aws rds-data execute-statement --resource-arn $AURORA_ARN --secret-arn $SECRET_ARN --database 'glueworkshop' --sql "CREATE TABLE orders ( orderid INT NOT NULL, item VARCHAR(1000) NOT NULL, price DECIMAL(6,2) NOT NULL, orderdate DATE, PRIMARY KEY (orderid) )" # データ登録 aws rds-data execute-statement --resource-arn $AURORA_ARN --secret-arn $SECRET_ARN --database 'glueworkshop' --sql "INSERT INTO orders VALUES(0,'Webcam',185.49,'2022-01-02')" # 以下複数データ登録(省略)
Glue Crawlerの実行
今回はCLIで実行してみます。
# Crawler Name取得 CRAWLER_NAME=$(aws cloudformation describe-stacks --stack-name WorkshopServerlessDatalakeStack --output text --query 'Stacks[0].Outputs[?OutputKey == `GlueCrawlerName`].OutputValue') # Crawler実行 aws glue start-crawler --name $CRAWLER_NAME # Crawlerのステータス取得 aws glue get-crawler --name $CRAWLER_NAME --query 'Crawler.State'
Crawlerのステータスとしては以下になります。実行完了後はREADYに戻るのでそれで完了したか判別が可能です(もちろんマネコンで見てもOK)。
State – UTF-8 string (valid values: READY | RUNNING | STOPPING). Indicates whether the crawler is running, or whether a run is pending.
Glue Jobの実行
ジョブもCLIで実行してみます。
# Job Name取得 JOB_NAME=$(aws cloudformation describe-stacks --stack-name WorkshopServerlessDatalakeStack --output text --query 'Stacks[0].Outputs[?OutputKey == `GlueJobName`].OutputValue') # ジョブ実行 aws glue start-job-run --job-name $JOB_NAME # ジョブのステータス取得 aws glue get-job-runs --job-name $JOB_NAME --max-results 1 --query 'JobRuns[0].JobRunState'
ジョブのステータスとしては以下があります。SUCCEEDEDになれば正常終了になります。
なお今回のようにFlexジョブを使用する場合、AWS側のリソースに余裕がないケースでは最大20分間WAITINGで待たされる可能性があるので注意が必要です。
A new job run will be in the WAITING state if the service is not able acquire enough resources to start the run, which delays the starting of the run. The run will be in WAITING state for a maximum of 20 minutes (timeout controlled by the service).
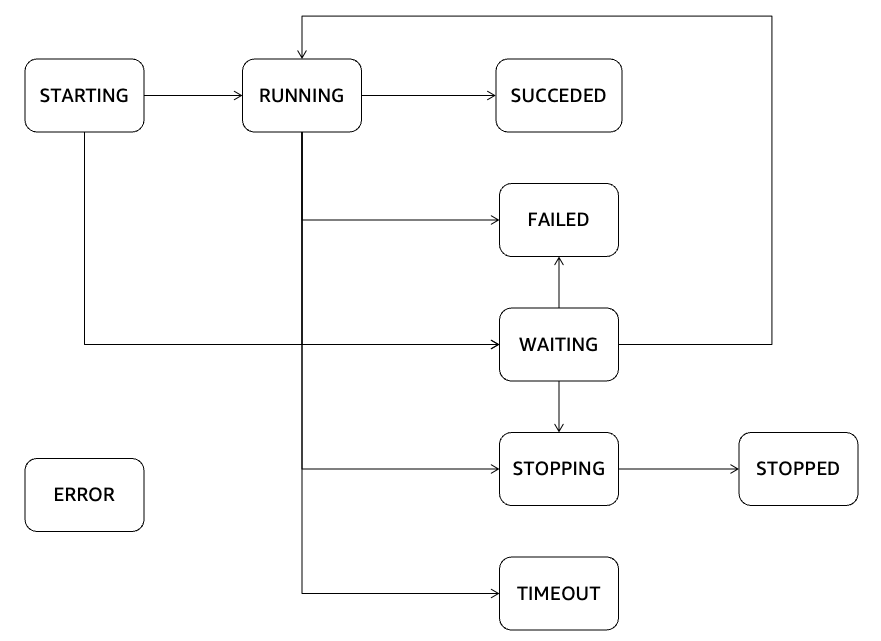 引用元:AWS Glue job run statuses - AWS Glue
引用元:AWS Glue job run statuses - AWS Glue
Athenaでクエリを投げて結果確認
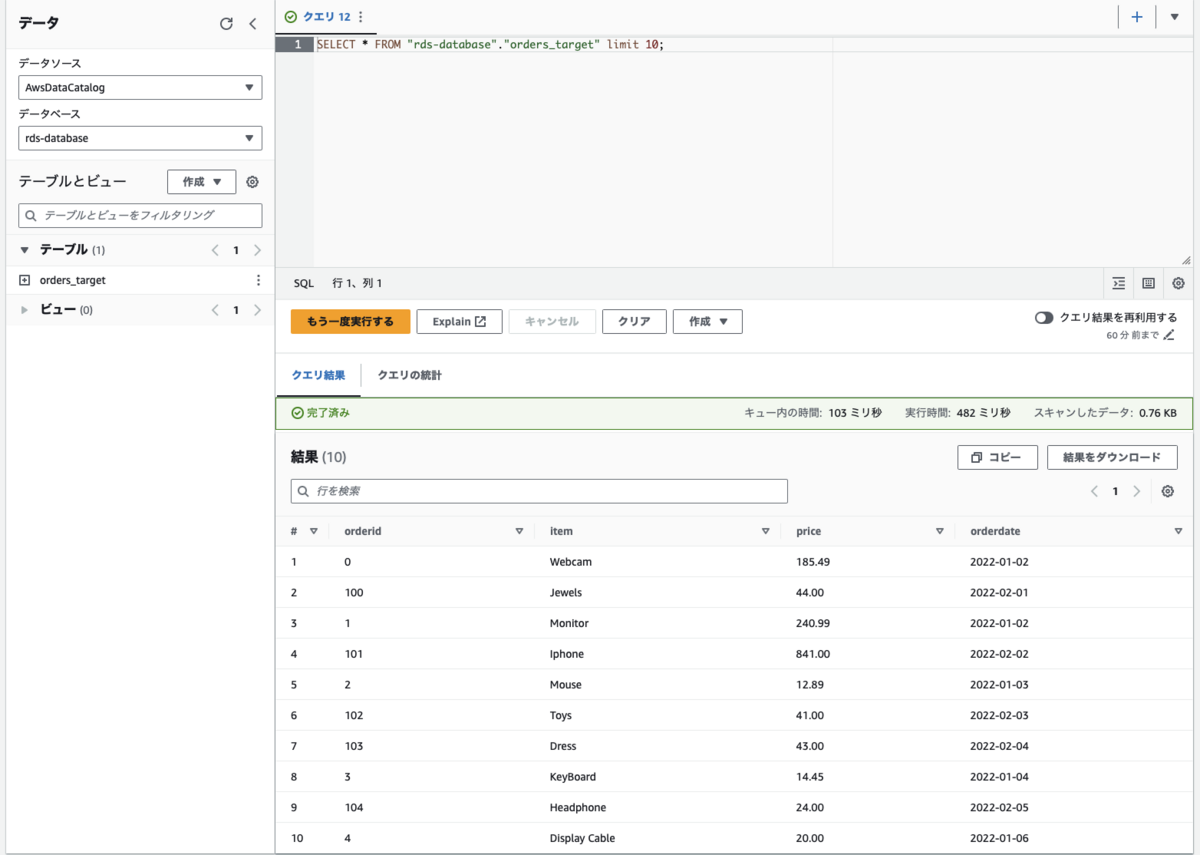
Glue JobでETL後のデータをS3に格納後、データカタログにテーブルを登録しているので、そのままAthenaでクエリを投げて結果を確認します。
以下のようにクエリを投げてみたところ、加工後のデータが取得できました。
参考(チューニングの資料)
上記でRDSのデータのクロールやETLが可能になりました。
一方でデータが多くなってくるとETL(Glue Job)の処理時間が長くなり、チューニングの必要性に迫られることがあります。
以下チューニングにおいて有益な資料をまとめておきます。
英語ですが、パフォーマンスチューニングの準備方法がまとめられています。 docs.aws.amazon.com
日本語の資料としては以下になります。3年弱前の資料ですが、今でも使える内容かと思います。