AWS Batch の理解があやふやな状態のまま使っていたので、学習し直すために AWS Batch Deep Dive(以下のWorkshop)を一通りCDKで実装してみました。
ECS on EC2 における AWS Batch について、様々なパターンのジョブを学習可能であり、コンテンツとして非常に有益でした。
なお AWS Batch は L2 Construct も存在しています。v2.74.0 からであり比較的新しいです。
目次
ハンズオンコンテンツ
以下のように配列ジョブなど様々なものが学習できます。
| No | Job | 説明 |
|---|---|---|
| 1 | Single job | 単一のJob実行について学ぶ。 |
| 2 | Array Job | 配列Jobについて学ぶ。 |
| 3 | Multi-node parallel Job | 複数のインスタンス上(マルチノード)で実行するジョブについて学ぶ。 |
| 4 | Jobs With dependencies | Job間で依存関係があるケースについて学ぶ。 |
| 5 | Jobs With dependencies (EC2 Spot) | Spotインスタンスの利用方法について学ぶ。実態はNo.4の一部がSpotインスタンスになったもの。 |
CDKプロジェクトについて
実装は以下に置いてあります。
ディレクトリ構成は以下です。
. ├── README.md ├── bin │ └── workshop_batch.ts ├── cdk.json ├── docs │ ├── array-job.drawio.svg │ ├── dependency-job-spot.drawio.svg │ ├── dependency-job.drawio.svg │ ├── multi-node-parallel-job.drawio.svg │ └── single-job.drawio.svg ├── jest.config.js ├── lib │ ├── constructs │ │ ├── ap # コンテナ資材を格納 │ │ ├── ecs-ec2-batch.ts # ECS on EC2によるAWS Batchの実装(Workshopのメイン) │ │ ├── ecs-fargate-batch.ts # ECS on FargateによるAWS Batchの実装(Workshopには登場しない) │ │ └── network.ts # ネットワーク(VPC)を定義 │ └── workshop_batch-stack.ts ├── package-lock.json ├── package.json ├── test │ └── workshop_batch.test.ts └── tsconfig.json
AWS Batchに関する実装は lib/constructs/ecs-ec2-batch.ts に行っています。Workshop はECS on EC2 のみですが、ECS on Fargate のパターンも別に実装してみました(lib/constructs/ecs-fargate-batch.ts )。
/lib/constructs/ap 配下にコンテナ関連の資材(Dockerfile等)を格納しています。
基本的にWorkshopのものそのままです。ただし手元の端末が M2 Mac(Apple Silicon)であったため、Dockerfileに一律 --platform=linux/amd64 を追加しアーキテクチャを明示しています。
FROM --platform=linux/amd64 public.ecr.aws/amazonlinux/amazonlinux:2
実装詳細について
実装が必要なリソース
AWS Batchのコンポーネントとしては以下の4つがあります。
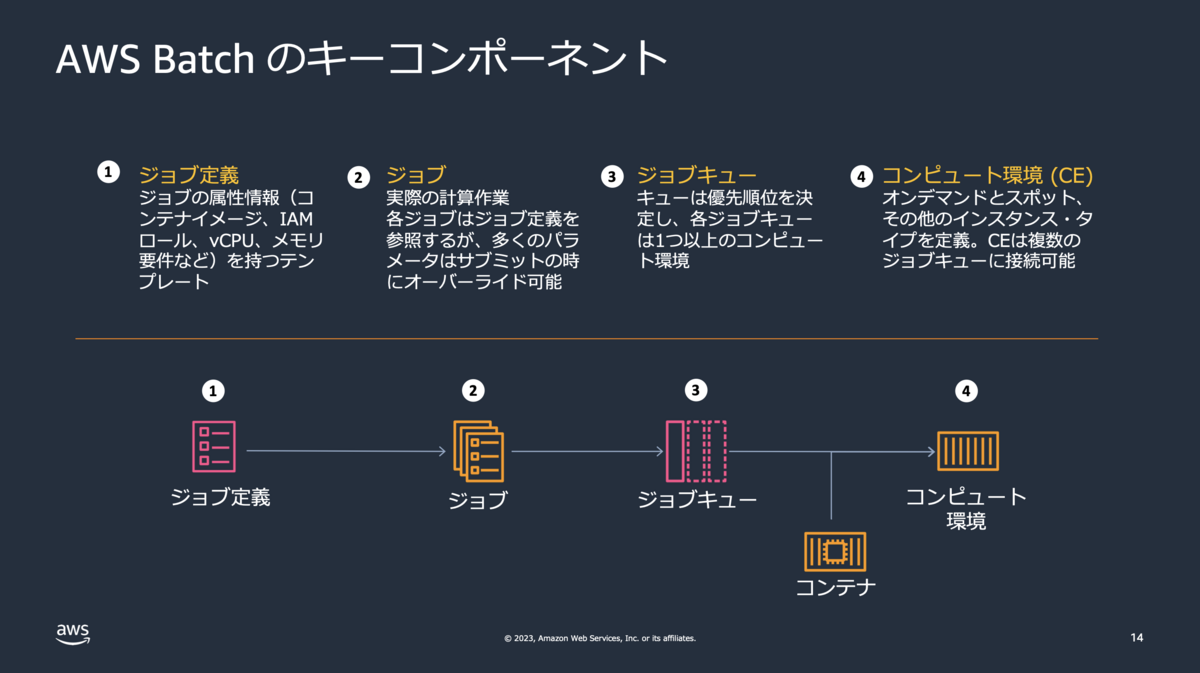 引用元:https://pages.awscloud.com/rs/112-TZM-766/images/AWS-Black-Belt_2023_AWS-Batch_0929_v1.pdf p14
引用元:https://pages.awscloud.com/rs/112-TZM-766/images/AWS-Black-Belt_2023_AWS-Batch_0929_v1.pdf p14
| No | コンポーネント名 | CDKにおける実装 |
|---|---|---|
| 1 | ジョブ定義 | コンテナの定義とジョブ定義を実装します。動作させるイメージごとに実装が必要。 |
| 2 | ジョブ | 実装不要。CDKで実装したジョブ定義やキューを元に、CLIやマネコンでジョブ実行します。 |
| 3 | キュー | No.4で実装したコンピュート環境に対して、キューを実装します。 |
| 4 | コンピュート環境 | コンテナを動作させる環境(ECS on EC2 / ECS on Fargate / EKS on EC2) |
ではWorkshopに沿って実装していきます。
パターン1. Single Job
シンプルに単一のジョブを一つ実行するパターンです。

Dockerfileの中身を見るとわかりますが、stress-ng を動かしているだけです(以下は一部抜粋したもの)
RUN echo $'#!/bin/bash\n\ echo "Passing the following arguments to stress-ng: $STRESS_ARGS"\n\ /usr/bin/stress-ng $STRESS_ARGS' >> /docker-entrypoint.sh RUN chmod 0744 /docker-entrypoint.sh RUN cat /docker-entrypoint.sh ENTRYPOINT ["/docker-entrypoint.sh"]
※ stress-ng は負荷をかけるツールです。
それではコンポーネントごとに実装していきます。
コンピュート環境
まずはコンテナを動作させるコンピュート環境から実装していきます。ECS on EC2のため ManagedEc2EcsComputeEnvironment を使用して実装します。
基本は真っ当に実装するのみです。インスタンスタイプでファミリー指定ができなかったので、複数設定してみました。
const computeEnvironment = new batch.ManagedEc2EcsComputeEnvironment(this, 'ComputeEnvironment', { vpc: props.vpc, maxvCpus: 256, minvCpus: 0, spot: false, allocationStrategy: batch.AllocationStrategy.BEST_FIT_PROGRESSIVE, computeEnvironmentName: 'stress-ng-ec2', // インスタンスタイプを指定 instanceTypes: [ ec2.InstanceType.of(ec2.InstanceClass.C7A, ec2.InstanceSize.MEDIUM), ec2.InstanceType.of(ec2.InstanceClass.C7A, ec2.InstanceSize.LARGE), ec2.InstanceType.of(ec2.InstanceClass.M7A, ec2.InstanceSize.MEDIUM), ec2.InstanceType.of(ec2.InstanceClass.M7A, ec2.InstanceSize.LARGE), ], // optimal を使いたくない場合はここをfalseにする。Gravitonを使いたい場合はここをfalseにしないとエラーになるので注意。 useOptimalInstanceClasses: false. })
ジョブキュー
次にジョブキューを実装します。コンピュート環境としては先ほど実装したものを指定します。複数の環境をオーダー付けして設定可能ですが、今回は1つのみ指定します。
new batch.JobQueue(this, 'JobQueue', { priority: 1, // 先ほど実装したコンピュート環境を指定 computeEnvironments: [ { computeEnvironment: computeEnvironment, order: 1 } ], jobQueueName: 'stress-ng-queue' })
ジョブ定義
まずはジョブで使うコンテナ定義 を実装します。
今回は Docker Image Assets を使い cdk deploy時にコンテナイメージもまとめてビルド・デプロイする方式としました。
またcpu は vCPU を設定するので注意が必要です(1 vCPU= 1024 CPU)。私は CPU を設定すると勘違いしてハマりました(ドキュメントをよく読んでないだけ)。
const containerDefinition = new batch.EcsEc2ContainerDefinition(this, 'ContainerDefinition', { // Docker Image Assets で cdk deploy時にビルド image: ecs.ContainerImage.fromAsset( path.resolve(__dirname, "./", "ap/single") ), cpu: 1, // vCPUを指定 memory: Size.mebibytes(1024), logging: new ecs.AwsLogDriver({ streamPrefix: 'single-job', logGroup: new logs.LogGroup(this, 'SingleJobLogGroup', { removalPolicy: RemovalPolicy.DESTROY, retention: RetentionDays.ONE_DAY }) }), })
次に ジョブ定義 を実装します。リトライの設定などはありますが、あまり難しいところはありません。
new batch.EcsJobDefinition(this, 'JobDefinition', { container: containerDefinition, // 先ほど実装したコンテナ定義を参照 timeout: Duration.seconds(180), retryAttempts: 3, jobDefinitionName: 'stress-ng-job-definition' })
ジョブ実行
ここまで終われば以下の CLI でジョブ実行が可能です。もちろんマネコンでやっても良いです。
# ジョブ名を指定 export SINGLE_JOB_NAME="stress-ng-1" # キューやジョブ定義の名称を指定(CDKの実装と合わせる) export SINGLE_JOB_QUEUE="stress-ng-queue" export SINGLE_JOB_DEFINITION="stress-ng-job-definition" # コンテナで使用する環境変数を設定 export SINGLE_STRESS_ARGS="--cpu 1 --cpu-method fft --timeout 1m --times" # ジョブをsubmit aws batch submit-job --job-name "${SINGLE_JOB_NAME}" --job-queue "${SINGLE_JOB_QUEUE}" --job-definition "${SINGLE_JOB_DEFINITION}" --container-overrides "environment=[{name='STRESS_ARGS',value='${SINGLE_STRESS_ARGS}'}]"
パターン2. Array Job
配列ジョブで、複数の子ジョブを実行します。

こちらも stress-ng を動かしています。子ジョブごとに実行するコマンドが変わるように制御されています。
- コンテナイメージにビルド時に
--cpu-method(負荷をかける方法) の一覧を取得して、1行ずつstress-ng実行のための引数を txt に書き込み。 - 実行時に、txt から引数を取得して
stress-ngを実行。この際AWS_BATCH_JOB_ARRAY_INDEXで自身の配列を取得している。
コンピュート環境、ジョブキュー
パターン1で実装したものをそのまま使うため割愛します。
ジョブ定義
コンテナ定義とジョブ定義を実装します。 ただし実装上はパターン1とほぼ同様です(コンテナ資材やリソース名が異なるだけ)。
そのため割愛します。
ジョブ実行
# ジョブ名を指定 export ARRAY_JOB_NAME="job-array-5" # 配列のサイズ(子ジョブの数を指定) export ARRAY_JOB_SIZE=5 # キューやジョブ定義の名称を指定(CDKの実装と合わせる) export ARRAY_JOB_QUEUE="stress-ng-queue" export ARRAY_JOB_DEFINITION="stress-ng-array-job-definition" # ジョブをsubmit aws batch submit-job --job-name "${ARRAY_JOB_NAME}" --job-queue "${ARRAY_JOB_QUEUE}" --job-definition "${ARRAY_JOB_DEFINITION}" --array-properties size="${ARRAY_JOB_SIZE}"
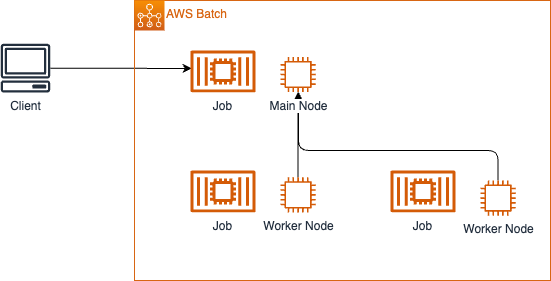
パターン3. Multi-node Parallel Job
複数のEC2インスタンス上でジョブを並列実行します。Workshopでは python のライブラリである Dask が使われています。
ノード間での通信が発生します。
コンピュート環境、ジョブキュー
パターン1で実装したものをそのまま使います。
一点追加で、ノード間通信が発生するためセキュリティグループで通信の許可設定を行います。
// ノード間通信のため同一SGからの接続を許可 computeEnvironment.connections.allowInternally(ec2.Port.allTcp())
ジョブ定義
コンテナ定義はパターン1, パターン2と同様です。
ジョブ定義は今までと異なり、MultiNodeJobDefinition で実装します。
containers で対象のコンテナを指定します。今回は同一のコンテナ定義で3つノード(配列で0-2)としていますが、ノードごとに異なるコンテナ定義にすることも可能です。
new batch.MultiNodeJobDefinition(this, 'MultiNodeJobDefinition', { // ノード0〜ノード2で同一コンテナ定義を指定 containers: [{ container: multiNodeContainerDefinition, startNode: 0, endNode: 2 }], timeout: Duration.seconds(180), retryAttempts: 3, jobDefinitionName: 'mnp-job-definition' })
コマンド実行
# ジョブ名を指定 export MNP_JOB_NAME="mnp-1" # キューやジョブ定義の名称を指定(CDKの実装と合わせる) export MNP_JOB_QUEUE="stress-ng-queue" export MNP_JOB_DEFINITION="mnp-job-definition" # ジョブをsubmit aws batch submit-job --job-name "${MNP_JOB_NAME}" --job-queue "${MNP_JOB_QUEUE}" --job-definition "${MNP_JOB_DEFINITION}"
パターン4. Jobs with dependencies
複数のジョブ間で依存関係があるパターンです。Workshopでは Leader がS3バケットに txt を格納 → Worker がそれを読み取って処理となっているので依存関係が発生しています。

なおコンテナで実行している内容はパターン2とほぼ同様です。
* パターン2は 1つのイメージの中でビルド時にtxtを生成 → txtを読み込んで stress-ng を実行
* パターン4は Leader ジョブが txt を生成しS3に格納 → Follower ジョブがtxtを読み込んで stress-ng を実行(複数のジョブで役割分担&ジョブ間でtxtをS3経由で受け渡し)
コンピュート環境、ジョブキュー
パターン1で実装したものをそのまま使います。
一点追加しているのはS3バケットの権限です。
// txt格納用のS3バケットを定義 const bucket = new s3.Bucket(this, 'Bucket', { autoDeleteObjects: true, removalPolicy: RemovalPolicy.DESTROY }) // あとでCLIでバケット名を取得するためにエクスポート new CfnOutput(this, 'BucketName', { value: bucket.bucketName, exportName: 'Bucket', key: 'Bucket' }); // インスタンスロールにS3の権限付与 bucket.grantReadWrite(computeEnvironment.instanceRole!)
後述のジョブロールにS3の権限を付与すればよく、インスタンスロールには不要では?と思ったのですが、試してみたところインスタンスロールにも付与しないとダメでした。
以下にあるようにインスタスロール、ジョブロールが両方存在する場合は両方に許可しておく必要があるそう。
なおAWS Batchに登場するロールは以下の記事が非常にわかりやすいです。
ジョブ定義
ここは今までと同様です。
一点異なるのはタスクロールにS3の権限を付与している点です。
bucket.grantReadWrite(leaderContainerDefinition.executionRole) bucket.grantReadWrite(followerContainerDefinition.executionRole)
ジョブ実行
以下のコマンドで実行可能です。
Follower ジョブにて、Leader ジョブのIDを元に依存関係を明示していることがわかります。またFollowerジョブはパターン2の配列ジョブになっています(子ジョブが12個)。
# S3バケット名を取得 export STRESS_BUCKET="s3://$(aws cloudformation describe-stacks --stack-name WorkshopBatchStack --output text --query 'Stacks[0].Outputs[?OutputKey == `Bucket`].OutputValue')" echo "${STRESS_BUCKET}" # Leader ジョブを実行し、結果を格納 export LEADER_JOB=$(aws batch submit-job --cli-input-json '{"jobName": "stress-ng-leader", "jobQueue": "stress-ng-queue", "jobDefinition": "stress-ng-leader-job-definition", "containerOverrides": {"environment": [{"name": "STRESS_BUCKET", "value": "'"$STRESS_BUCKET"'"}]}}') # Leader ジョブの実行結果から、ジョブIDを取得 export LEADER_JOB_ID=$(echo ${LEADER_JOB} | jq -r '.jobId') echo "${LEADER_JOB_ID}" # Follower ジョブを実行。--depends-on jobId で Leader ジョブに依存していることを明示。 aws batch submit-job --cli-input-json '{"jobName": "stress-ng-follower", "jobQueue": "stress-ng-queue", "arrayProperties": {"size": 2}, "jobDefinition": "stress-ng-follower-job-definition", "containerOverrides": {"environment": [{"name": "STRESS_BUCKET", "value": "'"$STRESS_BUCKET"'"}]}}' --depends-on jobId="${LEADER_JOB_ID}" --array-properties size=12
パターン5. Jobs with dependencies (Spot)
一つ前のパターンの亜種です。Follower が Spotインスタンス上での動作に変わっている点が異なります。

コンピュート環境、ジョブキュー
Follower のコンピュート環境がSpotインスタンスなので、新たに実装が必要です。
// Spot用のコンピュート環境を定義 const computeEnvironmentSpot = new batch.ManagedEc2EcsComputeEnvironment(this, 'ComputeEnvironmentSpot', { vpc: props.vpc, maxvCpus: 256, minvCpus: 0, spot: true, // Spotに関する設定 spotBidPercentage: 100, // Spotに関する設定 allocationStrategy: batch.AllocationStrategy.SPOT_CAPACITY_OPTIMIZED, // Spotに関する設定 computeEnvironmentName: 'stress-ng-ce-spot', instanceTypes: [ ec2.InstanceType.of(ec2.InstanceClass.C7A, ec2.InstanceSize.MEDIUM), ec2.InstanceType.of(ec2.InstanceClass.C7A, ec2.InstanceSize.LARGE), ec2.InstanceType.of(ec2.InstanceClass.M7A, ec2.InstanceSize.MEDIUM), ec2.InstanceType.of(ec2.InstanceClass.M7A, ec2.InstanceSize.LARGE), ], useOptimalInstanceClasses: false }) // S3へのアクセス権限を付与 bucket.grantReadWrite(computeEnvironmentSpot.instanceRole!) // Spot用のジョブキューを定義 new batch.JobQueue(this, 'JobQueueSpot', { priority: 1, computeEnvironments: [ { computeEnvironment: computeEnvironmentSpot, order: 1 } ], jobQueueName: 'stress-ng-queue-spot' })
ジョブ定義
コンテナ定義はパターン4の Follower のものを使います。
ジョブ定義は リトライ戦略を新たに設定したものを実装しています。
new batch.EcsJobDefinition(this, 'FollowerSpotJobDefinition', { container: followerContainerDefinition, timeout: Duration.seconds(180), jobDefinitionName: 'stress-ng-follower-spot-job-definition', retryAttempts: 5, retryStrategies: [ batch.RetryStrategy.of(batch.Action.RETRY, batch.Reason.custom({ onStatusReason: 'Host EC2*', })), batch.RetryStrategy.of(batch.Action.EXIT, batch.Reason.custom({ onReason: '*', })), ] })
ジョブ実行
以下のコマンドで実行可能です。
Follower ジョブにて、Leader ジョブのIDを元に依存関係を明示していることがわかります。またFollowerジョブはパターン2の配列ジョブになっています(子ジョブが12個)。
# S3バケット名を取得 export STRESS_BUCKET="s3://$(aws cloudformation describe-stacks --stack-name WorkshopBatchStack --output text --query 'Stacks[0].Outputs[?OutputKey == `Bucket`].OutputValue')" echo "${STRESS_BUCKET}" # Leader ジョブを実行し、結果を格納 export LEADER_JOB=$(aws batch submit-job --cli-input-json '{"jobName": "stress-ng-leader", "jobQueue": "stress-ng-queue", "jobDefinition": "stress-ng-leader-job-definition", "containerOverrides": {"environment": [{"name": "STRESS_BUCKET", "value": "'"$STRESS_BUCKET"'"}]}}') # Leader ジョブの実行結果から、ジョブIDを取得 export LEADER_JOB_ID=$(echo ${LEADER_JOB} | jq -r '.jobId') echo "${LEADER_JOB_ID}" # Follower ジョブを実行。--depends-on jobId で Leader ジョブに依存していることを明示。 aws batch submit-job --cli-input-json '{"jobName": "stress-ng-follower-spot", "jobQueue": "stress-ng-queue-spot", "arrayProperties": {"size": 2}, "jobDefinition": "stress-ng-follower-spot-job-definition", "containerOverrides": {"environment": [{"name": "STRESS_BUCKET", "value": "'"$STRESS_BUCKET"'"}]}}' --depends-on jobId="${LEADER_JOB_ID}" --array-properties size=12
その他
ベストプラクティスについて
そもそもAWS Batchいつ使うの、EC2 と Fargate どっちがいいの、など色々考えることがありますが以下の記事にまとまっていました。
AWS Batch を検討する場合は必読かと。
RUNNABLE で止まってしまう理由の調査
AWS Batch でよくあるトラブルの一つとして、ステータスが RUNNABLE のまま止まってしまうものがあります。
設定ミスのケースなどに起こるのですが、エラーログなどが明に出ないため原因調査が実施しづらいという問題がありました。
しかし2024/3のアップデートで、RUNNABLE で止まってしまう理由を取得できるようになりました。
以下はAWS CLIの describe-jobs で調査した場合です。ジョブのリソース設定がコンピュート環境のリソースを超えている(リソースが割り当てられない)ため止まっていることがわかります。
aws batch describe-jobs --jobs <JOB_ID> # 結果 { "jobs": [ { "jobArn": "arn:aws:batch:ap-northeast-1: 123456789012:job/JOB_ARN", "jobName": "stress-ng-1", "jobId": "JOB_ID", "jobQueue": "arn:aws:batch:ap-northeast-1:123456789012:job-queue/stress-ng-queue", "status": "RUNNABLE", "attempts": [], "statusReason": "MISCONFIGURATION:JOB_RESOURCE_REQUIREMENT - The job resource requirement (vCPU/memory/GPU) is higher than that can be met by the CE(s) attached to the job queue.", ... 以下略 } ] }
終わりに
内容盛りだくさんのWorkshopで AWS Batch (ECS on EC2) を学ぶには非常に有益でした。このWorkshopの内容を理解すれば ECS on Fargateのケースでも容易に実装できるかと思います。
なお別の Workshop で AWS Batch (EKS on EC2) も提供されています。こちらも機会があれば実施してみたいと思います。