以下のAWSにおけるMQTT通信シリーズの続編です。
今まではMQTTブローカーとしてのAmazon MQとAWS IoT Coreの比較、Amazon MQのフェイルオーバーを考慮したMQTTの実装例を解説しました。
今回はAWS IoT Core(以下IoT Core)を使ったMQTT通信を試します。
IoT Coreの特徴である他のAWSサービスとの連携が豊富である点を活かし、Rule Actionを使ったLambda連携、Kinesis Data Streams+Lambdaによるデータ処理など実践的な構成にしています。
IoTデバイスとサーバーがMQTTを使用してProtocol Buffersでやりとりする+IoTデバイスのデータを格納するデータ基盤から成ります。

目次
アーキテクチャについて
大きくは以下の3つの要素が存在します。
- MQTTクライアント:MQTT通信を行うクライアントアプリを作成。以下2種類作成しています。
- MQTTブローカー:MQTTクライアントが通信するために使用するブローカー
- IoTデバイスのデータを格納するデータ基盤:デバイスから配信されるTelemetryを元に、Topic RuleをトリガーしてAmazon Timestreamに取り込む基盤。
1の実装例はWeb上にもいくつかあること、2は実際そこまでやることがないので、記事の内容は3がメインになります。
なお、今回MQTTクライアントから配信するメッセージはProtocol Buffers(以下protobuf)を採用しています。
protobufはデータをシリアライズした形でやりすることから転送量を削減できるため、IoTの分野で使われることも多いです。
コードについて
以下に格納しています。
1. MQTTクライアントの実装

PythonとJavaでMQTTクライアント(アプリ)を実装しています。いずれもオープンソースのPahoを使用しています。
実装例は以下などがあります。
特記事項として、今回クライアント証明書による認証としたいため、ルート証明書、クライアント証明書、クライアント秘密鍵を設定しています。
以下Pythonの場合の実装イメージです。
client = mqtt.Client(protocol=mqtt.MQTTv311, client_id=client_name, clean_session=None) # SSL/TLSのコンテキストを作成 context = ssl.create_default_context() # ルート証明書、クライアント証明書、秘密鍵をコンテキストに設定 context.load_verify_locations(cafile=self.cafile) context.load_cert_chain(certfile=self.certfile, keyfile=self.keyfile) # クライアントにコンテキストを設定 client.tls_set_context(context=context)
一方Javaでハマった点として、秘密鍵の形式です。標準クラスで扱えるのはPKCS#8のみであるため変換をする必要がありました。
そのため例えばAWS IoT Coreで取得した秘密鍵を使用する際は、以下のコマンドで変換を行います。
openssl pkcs8 -topk8 -inform PEM -outform DER -nocrypt -in iotcore/certs/private.key -out iotcore/certs/private_pkcs8.key
変換後の秘密鍵を以下で読み込んでいます。全量の実装は長いので秘密鍵の部分のみ抜粋しています。
// 秘密鍵の読み込み FileInputStream clientKeyFile = new FileInputStream(this.clientKeyFilePath); byte[] keyBytes = clientKeyFile.readAllBytes(); clientKeyFile.close(); PKCS8EncodedKeySpec keySpec = new PKCS8EncodedKeySpec(keyBytes); KeyFactory keyFactory = KeyFactory.getInstance("RSA"); PrivateKey privateKey = keyFactory.generatePrivate(keySpec);
参考(SDKについて)
今回はPahoを使用しましたが、AWS IoT CoreのSDKを使用する方法もあります。例えばPythonの実装例は以下です。
またJavaでは aws-iot-device-sdk-javaがあります。注意点としてMQTTのpublishにおいて Blocking API を使用した場合、サーバーとの通信に異常が発生しPublishに対するレスポンスがない場合無限待ちとなり、処理がストップしてしまう可能性があります(経験談)。
基本的にはタイムアウト付きのAPIを使い、異常時はタイムアウトによる制御を行うのが望ましいと考えます。
aws-iot-device-sdk-java-docs.s3-website-us-east-1.amazonaws.com
2. MQTTブローカー

今回はAWS IoT Coreを使用することを念頭に、ローカルでのクライアント開発用にmosquittoでMQTTブローカーを構築しています。
AWS IoT Coreと同様に、クライアント証明書による認証としたかったため、以下のようにmosquitto.confにおいて各種証明書、秘密鍵を設定した上で、証明書を要求する形にしています(事前に自己署名証明書の用意などは行なっておく)。
# MQTTSのポートを設定 port 8883 # 証明書のパスを設定 cafile /mosquitto/config/certs/ca.crt certfile /mosquitto/config/certs/broker.crt keyfile /mosquitto/config/certs/broker.key # 証明書を必須にする require_certificate true allow_anonymous true
上記を元にdocker composeで立ち上げられるよう、compose.yamlを作成しています。
これでローカル開発時は mosquitto で検証しつつ、AWS環境ではIoT Coreを使うということができるようになりました。
一方AWS IoT Coreを使う場合、各種証明書や秘密鍵を生成しダウンロード、および証明書にポリシーをアタッチすることでMQTT通信が可能になります。Amazon MQやmosquitto等と違い、MQTTブローカーの実体を意識せずに通信が行えるのは便利ですね。
マネコンにおける設定手順としては以下が参考になります(AWS IoT Coreのワークショップ)
catalog.us-east-1.prod.workshops.aws
3. IoTデバイスのデータを格納するデータ基盤
前置きが長くなりましたがメインの箇所です。
IoTデバイスがMQTTでPublishするデータについて、単純にサーバーでSubscribeしてもいいですが、大量のデバイスがPublishした際などにサーバーに負荷がかかりそうです。
そのためサーバーレスなデータ基盤を構築してみます。
アーキテクチャとしては以下になります。CDKの実装も交えつつ順番に詳細を見ていきます。CDKの実装全量はリポジトリのcdk配下に配置しています。

この構成とした理由は以下です。
- 全般的にサーバーレスなサービスを活用し、運用負荷を抑えスケーラブルなIoTデータ取り込み基盤を構築したい。
- IoTデバイスとの通信は軽量なprotobufを使いつつも、サーバー側では入り口でデシリアライズして扱いやすくしたい。
- 大量のデータを扱うケースを考慮し、Kinesis Data Streamsをデータ取り込みのLambdaの前段に配置。
- IoTのデータは時系列であることが多いので、時系列データベースであるTimestreamを採用。
(a).protobufを変換しKDSに流す
ここでは以下を作成していきます。
- protobufデシリアライズ用のLambda関数(IoT CoreのTopic Ruleから呼び出し)
- Topic Rule
- Topic Ruleから配信を行うKinesis Data Streams(KDS)

今回デバイスがpublishするメッセージはprotobufを使用しているためシリアライズされています。軽量なため通信帯域等が限られるIoTデバイスとの通信ではメリットがある一方で、データの加工や処理が難しいです。
そのため入口(IoT Core)の部分でデシリアライズすることを考えます。
今回は以下のAWS記事で採用されている、Topi Ruleでデシリアライズする方法を採用します。 protobufのメッセージを受信[1]したタイミングで、IoT CoreのTopic Ruleからデシリアライズ用のLambda[2]を呼び出しています。

このデシリアライズの特徴は、IoT RuleのSQLからLambdaを呼び出している点です(以下が例)。
SELECT aws_lambda("arn:aws:lambda:us-east-1:ACCOUNT_ID:function:my-protobuf-decoder", {"data": encode(*, "base64"), "clientId": clientId()}) as payload, timestamp() as p_time FROM 'connected-cars/data'
IoT RuleはSQLを活用して後続のサービスに受け渡すデータの加工が行えますが、より高度な変換をしたい場合にLambda関数を呼び出すことも可能です。ただし制約としてLambdaの実行時間が2000ms以内の必要があります。
今回はデシリアライズ用のLambda関数を実装し、IoT Topic RuleからSQLで呼び出すよう設定し、マネージドな仕組みでデシリアライズを行います。その上で加工したデータをKinesis Data Streamsに送信するようにします。
事前準備として、Protocol Buffersを扱うためにLambdaのLayerを用意しておく必要があります。
上記AWS公式ブログに作成方法の例が載っています。今回は例を参考にprotobuf配下に資材を作成してみます。
最終的な完成イメージは以下です。
├── protobuf │ └── python │ ├── custom │ ├── google │ └── protobuf-4.23.3.dist-info
AWS公式ブログのコマンドを参考にLayerを作成していきます。以下コマンド例です(protobuf配下で実施を想定)。
# protobuf 配下に python を作成し、protobuf をインストール mkdir python cd python pip3 install protobuf --target . # python 配下に custom を作成し、Protocol Buffersのファイルをコピー mkdir custom cd custom cp ../../../dummy_telemetry_pb2.py . # lambda から importするための定義 # 以下により Lambda(python)でfrom custom import dummy_telemetry_pb2 で import が可能。 echo 'custom' >> ../protobuf-*.dist-info/namespace_packages.txt echo 'custom/dummy_telemetry_pb2.py' >> ../protobuf-*.dist-info/RECORD echo 'custom' >> ../protobuf-*.dist-info/top_level.txt # AWS CLIでLayerを登録する場合はzip化した上で実施。AWS CDKでLayerを作成する場合zip化は不要。 cd ../../ zip -r protobuf.zip . aws lambda publish-layer-version --layer-name protobuf --zip-file fileb://protobuf.zip --compatible-runtimes python3.8
Layerの準備ができたので、CDKで実装していきます。特記事項がある点は★を追記しているので後ほど触れます。
import { aws_lambda as lambda } from 'aws-cdk-lib'; import { aws_logs as logs } from 'aws-cdk-lib'; import { aws_kinesis as kinesis } from 'aws-cdk-lib'; // iot関係はalphaモジュールを使用 ★① import * as iot from '@aws-cdk/aws-iot-alpha' import * as actions from '@aws-cdk/aws-iot-actions-alpha' // omit // Layerを作成。コマンドで作成したLayerをプロジェクトに配置し、指定したパスに配置 ★② const protobufLayer = new lambda.LayerVersion(this, 'ProtobufLayer', { code: lambda.AssetCode.fromAsset('lambda/layer/protobuf'), compatibleRuntimes: [lambda.Runtime.PYTHON_3_9], }); // Lambda関数を作成 const protobufFunction = new lambda.Function(this, 'ProtobufFunction', { // omit }); // Kinesis Data Streamsのストリームを作成 const stream = new kinesis.Stream(this, 'Streams', {}) // IoT Topic Rule const topicRule = new iot.TopicRule(this, 'TopicRule', { topicRuleName: 'MqttTopicRule', description: 'invokes the lambda function', // デシリアライズ用のLambdaを呼び出すSQLを定義 ★③ sql: iot.IotSql.fromStringAsVer20160323(`SELECT aws_lambda('${protobufFunction.functionArn}',{'data': encode(*, 'base64')}) as payload FROM 'python/messages/#'`), actions: [ // Topic RuleからKinesis Data Streamsに配信するアクションを定義。 new actions.KinesisPutRecordAction(stream, { partitionKey: '${newuuid()}', }) ] });
① AWS IoT Core関連のalphaモジュールを使用
CDK(v2.86.0)時点ではIoT Coreの正式なL2 Constructは存在しません。L1 Constructを使う選択肢もありますが、今回は以下のalphaモジュールを使うことにしました。
@aws-cdk/aws-iot-alpha module · AWS CDK
@aws-cdk/aws-iot-actions-alpha module · AWS CDK
alphaモジュールはCDK本体に含まれないため個別にnpm installした上でimportが必要です。
npm install @aws-cdk/aws-iot-alpha npm install @aws-cdk/aws-iot-actions-alpha
② LambdaのLayer作成
事前準備で作成したLayerの資材を配置していきます。
├── lambda │ └── layer │ └── protobuf │ └── python
③ デシリアライズ用のLambda関数をTopic Ruleから呼び出すSQLを作成
以下SQLの部分のみ抜き出しています。
SELECT -- デシリアライズ用のLambdaを呼び出す。 -- Lambdaの入力データはbase64にエンコードしたものを渡す。 aws_lambda( '${protobufFunction.functionArn}', { 'data': encode(*, 'base64') } -- Lambdaからの出力は payload 配下に格納 ) as payload -- MQTT topic名を指定してそこに配信されたメッセージを処理対象とする。 FROM 'python/messages/#'
ここでハマったのが、Lambdaの入力データに関するところです。protobufの生のデータをそのまま渡すのではなく、一旦base64でエンコードしJSONにしてから渡しています(以下のようなイメージ)。
{'data': 'CgxkdW1teV9jbGllbnQRzm3CvTLXQUAZNV66SYx4YUAiCwj8zYqlBhCI7+56'}
そのままprotobufの生データをLambdaに渡せばいいのでは?と思い試したところ、その場合Lambdaが実行すらされない状態になってしまいました。
おそらく以下の記事の内容が該当するかと思いますが、入力データをJSONにしないとうまくいかないようです。
そのためAWS公式の例に倣い、protobufの生データ(バイナリ)は一旦base64にエンコードし、JSONにした上でLambdaに渡しています。Lambda側ではbase64をデコードした上で、protobufをデシリアライズし、データを作成して返却する形にしています。
# base64をデコード payload_data_decoded = base64.b64decode(data) # protobufをデシリアライズ telemetry.ParseFromString(payload_data_decoded) # 出力用のデータを作成 data = { "id": telemetry.id, "latitude": telemetry.latitude, "longitude": telemetry.longitude, "timestamp": timestamp_value } # データを返却 return data
これでデシリアライズしたデータをIoT Topic Ruleから渡せるようになりました。SQLでは as payload としているので、JSONのpayload配下にデシリアライズしたデータが格納されます。
このデータをKinesis Data Streamsに渡していく形となります。なおKinesisは大量のデータを受信するケースを考慮し、バッファリング層とする為です。
IoTの分野ではテレメトリやセンサーデータを送るデバイスが大量に存在するケースもあるため、データのキューイング等が行えるKinesis Data Streamsを挟むのは一つのデザインパターンかと思います。
※捕捉
なおTopic RuleでLambdaを用いず直接protobufをデシリアライズする手法もあります。個人的には使い分けのポイントとしては以下かと思います。
- TopicルールからLambdaを呼び出す方式(今回):protobufのデコードと同時に値の加工も行いたい場合。こちらの方が汎用性は高いがレイヤーの用意など多少手間がかかる。またLambdaを呼び出しているためスロットリングには注意が必要。
- Topicルールで直接デシリアライズする方式:protobufのデコードのみを行えればいい場合。S3に設定ファイルをおく必要があるが、Lambdaを使う方式よりも設定が楽。またスロットリングを気にしなくてよい
(2024/3/26追記)Topicルールで直接でシリアライズする方式についても別記事で作成しました。
(b). KDSからLambdaをトリガー
Kinesis Data Streamsに流しからデータ登録用のLambda(Consumer)に流す箇所です。
LambdaとKDSから呼び出すためのトリガーを作成していきます
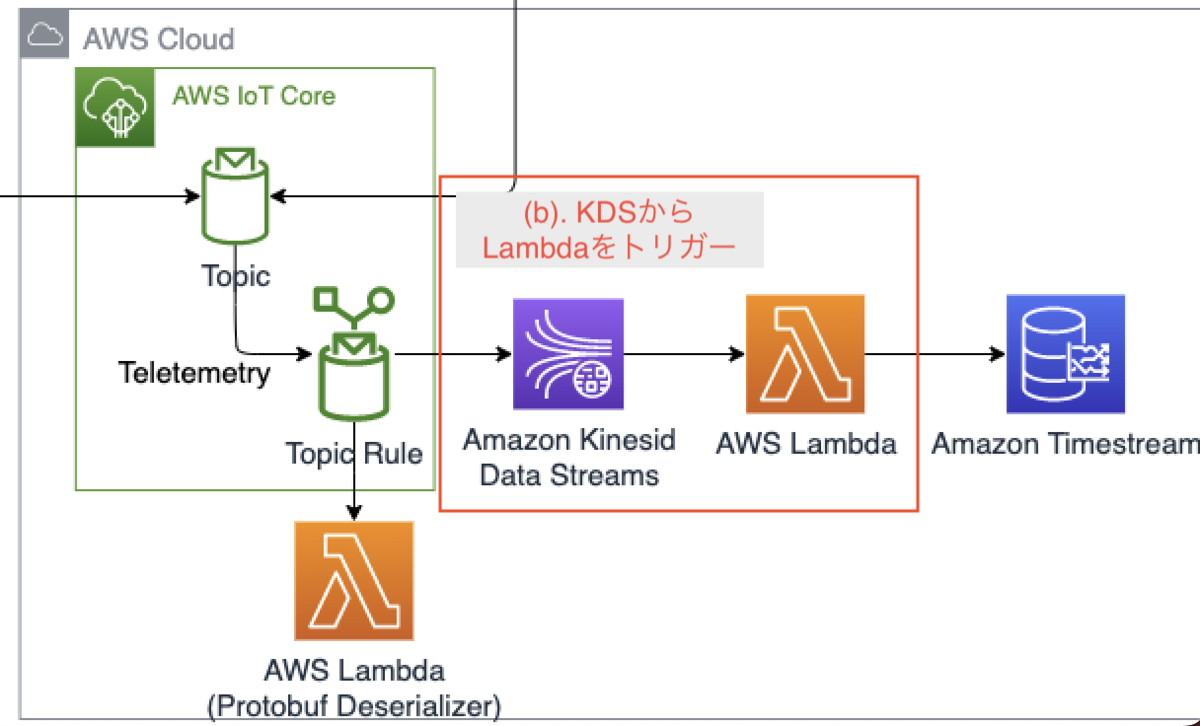
CDKの実装としては以下です。
// Lambda(Kinesis Data Streamsから呼び出されるConsumer) const consumerFunction = new lambda.Function(this, 'ConsumerFunction', { // omit } }); // LambdaのトリガーにKDSを設定 consumerFunction.addEventSource(new event_sources.KinesisEventSource(stream, { batchSize: 100, startingPosition: lambda.StartingPosition.TRIM_HORIZON, retryAttempts: 0 // リトライ回数をゼロに設定 }))
注意が必要なプロパティとして、KinesisEventSourceの retryAttempts があります。デフォルトだと、-1(データが期限切れになるまでリトライを繰り返す)なので、気をつけないと延々とリトライを繰り返す形になってしまいます。
今回は単純にリトライを0にしていますが、実システムではリトライの実施に加え、異常時のためのDLQの仕組みを設けるのがベターです。
※参考
また、KDSから配信されるデータはbase64でエンコードされているので、デコードした上で処理が必要です。今回は以下の記事の実装を参考にさせていただきました。
以下Lambdaのロジックの一部です。
# ペイロードを受信 for record in event['Records']: # Kinesis Data Streamsのデータ(base64)をデコード data = json.loads(base64.b64decode(record['kinesis']['data']).decode('utf-8')) payload = data["payload"]
(c). LambdaからTimestreamにwrite
最後にTimestreamを構築し、Lambda(Consumer)において書き込み処理を実装していきます。
Timestreamについて
今回時系列データの格納先としてTimestreamを使用しています。
今回のような時系列データの場合でもDynamoDBを使うケースはあると思います。一方で時系列データは様々な観点で分析をしたいケースも多々あるものの、DynamoDBは複雑なクエリで絞り込みなどを行うのが少々苦手です。
Timestreamは時系列データの扱いに適しており集計や複雑なクエリによる絞り込みが容易です。そのため今回は採用しました。
なお私見にはなりますが、Timestreamは比較的マイナーなDBかつ、レコードの更新・削除ができないなどクセもあるため、一般的なAPの処理のためのデータ格納としては少々採用しづらいイメージです。そのため私が使うとすれば分析用途としてTimestreamにデータは溜めつつも、APの処理に使うデータはDynamoDBやRDSに格納するというハイブリッド構成を取るかなと思います。
※参考
https://d1.awsstatic.com/webinars/jp/pdf/services/20201216_BlackBelt_AmazonTimestream.pdf
実装(CDK)
今回は以下のようにLambdaからTimestreamにデータを書き込みます。

CDKの実装としては以下です。
// Timestreamのデータベースとテーブルを作成 const timestreamDatabase = new timestream.CfnDatabase(this, 'Database', { databaseName: timestreamDatabaseName }) const timestreamTable = new timestream.CfnTable(this, 'Table', { databaseName: timestreamDatabaseName, tableName: timestreamTableName }) // テーブルとデータベースの依存関係定義 timestreamTable.addDependency(timestreamDatabase) // Lambda(consumer)からTimestreamに書き込みを行うための権限を付与 const timestreamPolicy = new iam.PolicyStatement({ actions: [ 'timestream:WriteRecords', ], resources: [ timestreamTable.attrArn ], }) const describeEndpointsPolicy = new iam.PolicyStatement({ actions: [ 'timestream:DescribeEndpoints', ], resources: ['*'], }) // ポリシードキュメントをLambda関数のロールに追加 consumerFunction.addToRolePolicy(timestreamPolicy); consumerFunction.addToRolePolicy(describeEndpointsPolicy);
まずTimestreamについては2023/7時点でL1 Constructしか存在しないのでそのまま実装します。データベースが構築できてから、テーブルを構築する必要があるのでaddDependencyで依存関係を定義しています。
次にconsumerのLambdaに書き込み権限を付与していきます。timestream:WriteRecordsは書き込み対象のテーブルに対してのみ付与することで問題ありません。timestream:DescribeEndpointsは書き込み対象のリソースだけではなく全般的に権限が必要なのでご注意ください。
実装(Lambda)
最後にTimestreamへの書き込み処理(Lambda)を実装します。
今回IoTデバイスから配信するTelemetryは緯度、軽度など複数の測定値を含みます。このようなデータはTimestreamでは「マルチメジャーレコード」として取り扱う形になります。
以下Lambdaの実装です。
payload = data["payload"] # ディメンションの設定 dimensions = [ {'Name': 'id', 'Value': payload['id']}, ] records = [] latitude = { 'Name': 'latitude', 'Value': str(payload['latitude']), 'Type': 'DOUBLE' } longitude = { 'Name': 'longitude', 'Value': str(payload['longitude']), 'Type': 'DOUBLE' } records.append(latitude) records.append(longitude) # マルチメジャーレコードのデータポイントの作成 data_point = { 'Time': str(payload['timestamp']), 'TimeUnit': 'MILLISECONDS', 'MeasureName': 'device_metrics', 'MeasureValueType': 'MULTI', 'MeasureValues': records, 'Dimensions': dimensions } print(data_point) # データポイントを書き込む try: response = timestream_client.write_records( DatabaseName='TelemetryDatabase', TableName='TelemetryTable', Records=[data_point] ) print(response) except Exception as e: // omit
なおLambdaを実装時に以下のエラーに苦戦しました。想定通りのタイムスタンプを設定してデータをインサートしようとしているにも関わらず、範囲外のエラーになるというものです。
The record timestamp is outside the time range [2023-07-02T08:25:00.627Z, 2023-07-02T15:05:00.627Z) of the memory store.
原因ですが、Timestreamに書き込む処理におけるタイムスタンプの単位の設定に問題がありました(以下のTimeUnit)。
data_point = {
'Time': str(payload['timestamp']),
'TimeUnit': 'MILLISECONDS', # タイムスタンプの単位を設定
'MeasureName': 'device_metrics',
'MeasureValueType': 'MULTI',
'MeasureValues': records,
'Dimensions': dimensions
}
当初Timeに秒単位のタイムスタンプ、TimeUnitは未指定としていました。しかしTimeUnitのデフォルトはMILLISECONDSはミリ秒のため単位が合わずにエラーとなっていました。
今回は最終的に全てミリ単位にすることで解消しています。時刻の単位には注意が必要です。
(捕捉)IoT Core Rule ActionからTimestreamに直接書き込むパターンについて
今回のようにLambdaを使わずとも、IoT Coreから直接Timestreamにデータを書き込むパターンもあります。
ただしこの方式はマルチメジャーレコードには非対応(執筆時点)です(シングルメジャーレコードにしか使えない)。
そのため今回のTelemetryのように複数の計測値を持つデータは、Lambda等を使用してマルチメジャーレコードとして格納が必要です。
動確
インフラ構築後、pythonのMQTTクライアントからIoT Coreのブローカーに対してDummyTelemetryを配信してみました。
問題なくTimestreamに登録されています。またTimestreamの長所でもあるSQLの分析なども問題なくできました。
スキーマレスかつサーバーレスなどDynamoDBのような特徴を持ちつつ、SQL等での分析も可能ということで分析用途には非常に適していると感じました。

おわりに
IoT Coreを使うとprotobufのデシリアライズ、AWSのサービスと組み合わせたサーバーレスなデータ処理など、AWSをフルに活用したIoTデータ処理基盤の構築が行えました。
Amazon MQで同様のことを行うのは難しく、やはりIoTデータを扱う上ではIoT Coreを使うのが非常に便利かと思います。
またTimestreamも時系列データの分析という観点では適しているため、分析用途のDBの選択肢として持っておきたいと思います。