最近の個人的イチオシ機能として、Step Functions で分散処理が行える DIstributed Map があります。分散処理させて問題ないかなどの考慮は必要ですが、適合するユースケースでは大幅な処理時間短縮も可能であり、効果が大きい機能だと思います。
ただ、設定項目が多く理解が中途半端なまま使っている感が否めなかったため、「完全に理解した」状態になるため整理を行いました。
また作成自体は今までASL作成やマネコンで行なっていたのですが、AWS CDK v2.127.0 で L2 Constructが実装されています。今回はこちらも試したいと思います(ASLも合わせて記載します)
AWS CDK v2.127.0 新機能✨#cdk_releases
— Kenji Kono (@konokenj) 2024年2月13日
1/ Step FunctionsのDistributedMap L2コンストラクトが追加
2/ SNS FIFO TopicにmessageRetentionPeriodInDaysプロパティが追加され、メッセージのアーカイブポリシーが設定可能に。Thank you @nixieminton !
3/ EKSでKubernetes v1.29をサポート
4/…
目次
導入
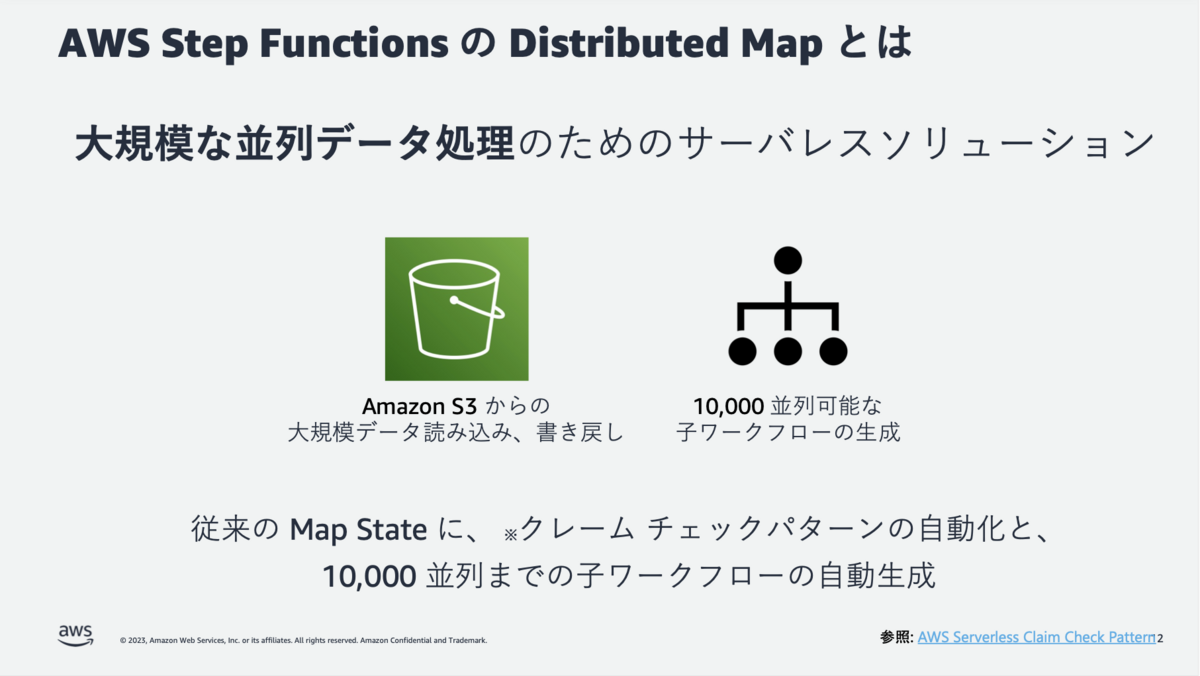
Step Functions Distributed Mapとは
Step Functionsで大規模な分散処理が行える機能です。
大量のファイル群や、大容量のファイルを最大10,000並列の子ワークフローで分散処理することが可能です。
 引用元:
https://pages.awscloud.com/rs/112-TZM-766/images/20230126_26th_ISV_DiveDeepSeminar_sfn_dmap.pdf
→ p12
引用元:
https://pages.awscloud.com/rs/112-TZM-766/images/20230126_26th_ISV_DiveDeepSeminar_sfn_dmap.pdf
→ p12
上記資料およびその動画が非常にわかりやすいです。
用いる題材
以下の Workshop Module 2 のステートマシンを活用します。S3上のファイルをLambdaで分散する処理するシンプルなものです。
catalog.us-east-1.prod.workshops.aws
実装
CDKの実装は以下のL2 Constructを使用します。
実装は以下にあります。 github.com
Distributed Mapの実装は以下の部分です。この後個別にみていきます。
// Distributed Map を定義
const distributedMap = new sfn.DistributedMap(this, 'MultiFileDistributedMap', {
label: 'Ditributedmaphighprecipitation',
itemReader: new sfn.S3ObjectsItemReader({
bucket: multiFileDataBucket,
prefix: "csv/by_station/noah"
}),
itemSelector: {
"Key": sfn.JsonPath.stringAt('$$.Map.Item.Value.Key')
},
itemBatcher: new sfn.ItemBatcher({
// 固定値の場合
// maxItemsPerBatch: 100,
// maxInputBytesPerBatch: 262144,
// 動的に変更したい場合
maxItemsPerBatchPath: sfn.JsonPath.stringAt('$.maxItemsPerBatch'),
maxInputBytesPerBatchPath: sfn.JsonPath.stringAt('$.maxInputBytesPerBatch')
}),
// 固定値の場合
// maxConcurrency: 1000,
// 動的に変更したい場合
maxConcurrencyPath: sfn.JsonPath.stringAt('$.maxConcurrency'),
mapExecutionType: sfn.StateMachineType.EXPRESS, // STANDARD or EXPRESS を選択。デフォルトは STANDARD
resultSelector: {
'result_bucket': sfn.JsonPath.stringAt('$.ResultWriterDetails.Bucket')
},
resultWriter: new sfn.ResultWriter({
bucket: multiFileResultsBucket,
prefix: "results"
}),
// 固定値の場合
toleratedFailureCount: 5,
toleratedFailurePercentage: 5,
// 動的に変更したい場合
// toleratedFailureCountPath: sfn.JsonPath.stringAt('$.toleratedFailureCount'),
// toleratedFailurePercentagePath: sfn.JsonPath.stringAt('$.toleratedFailurePercentage'),
})
// Lambda関数を呼び出すステートを定義
const highPrecipitationFunctionTask = new tasks.LambdaInvoke(this, 'HighPrecipitationFunctionTask', {
lambdaFunction: highPrecipitationFunction,
payload: sfn.TaskInput.fromJsonPathAt('$'),
outputPath: sfn.JsonPath.stringAt('$.Payload'),
retryOnServiceExceptions: false
})
highPrecipitationFunctionTask.addRetry({
maxAttempts: 6,
backoffRate: 2,
interval: cdk.Duration.seconds(2),
errors: [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
]
})
// DistributedMapにItemProcessorを設定
distributedMap.itemProcessor(highPrecipitationFunctionTask, {
})
// ステートマシンを定義
new sfn.StateMachine(scope, 'MultiFileStateMachine', {
definitionBody: sfn.DefinitionBody.fromChainable(distributedMap),
})
設定&実装詳細の解説
0. 全体像
以下が全体像になります。各フィールドごとに設定内容詳細を確認します。
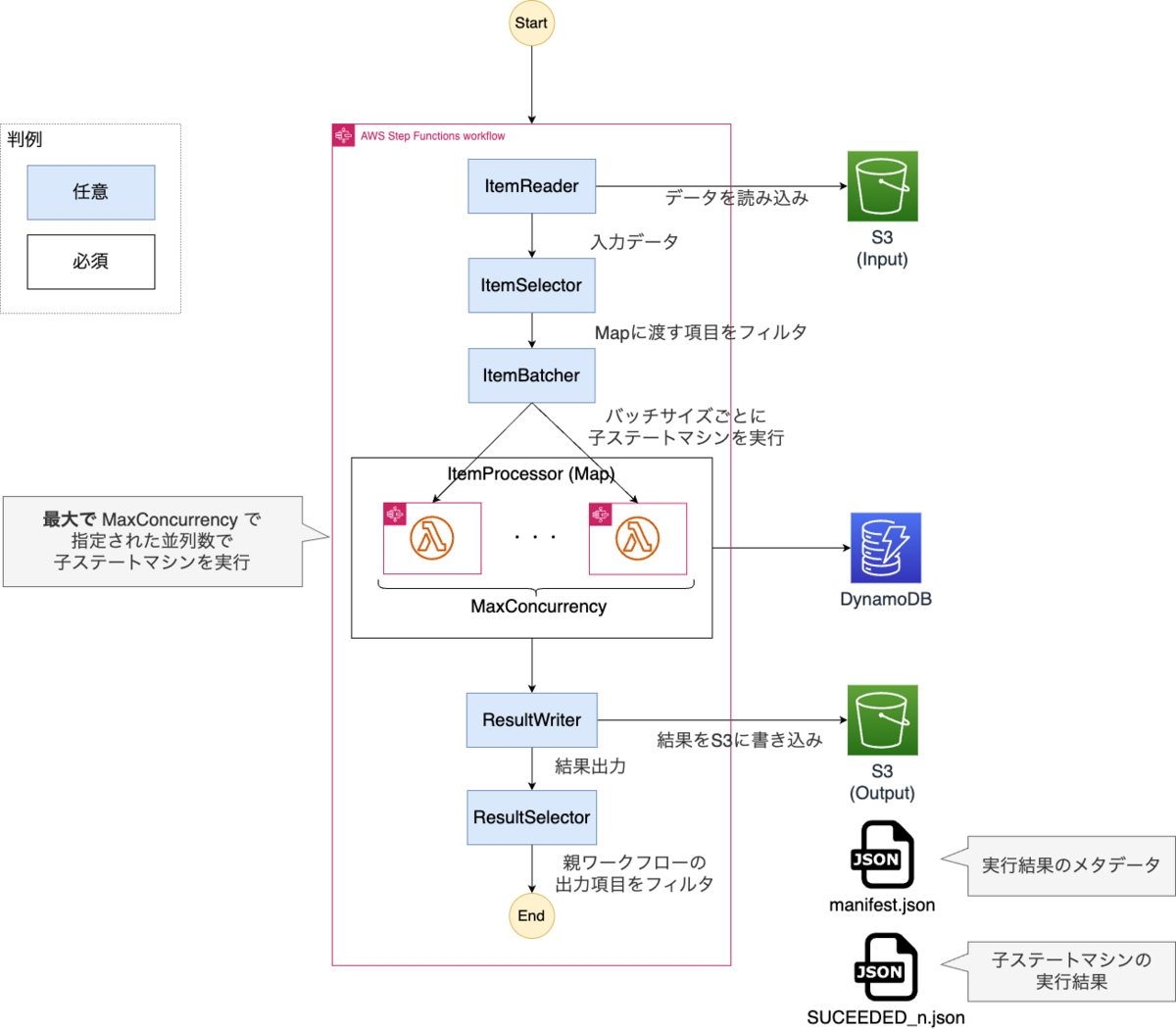
なお公式のドキュメントとしては以下になります。 docs.aws.amazon.com
1. ItemReader
S3から入力データを読み込むフィールドとなります。
なお、未定義の場合は前のステートからの入力がそのまま入ってきます。しかしDistributed Mapを使いたいのは大規模データを処理したいケースがほとんどかと思うので、S3からの読み込みを行うことが多いのではないかと思います。
入力としては大きく以下2パターンに分かれます。
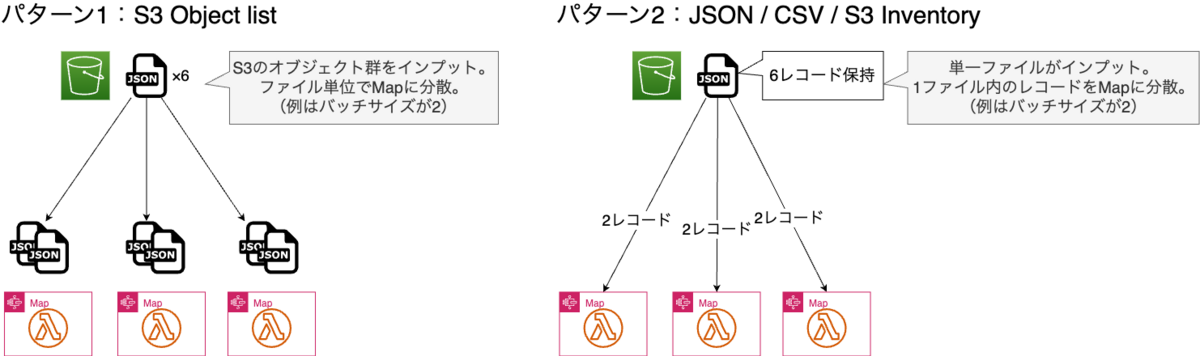
パターン1. S3 Object list(今回の題材はこちら)
S3内の複数ファイルをインプットとし、ファイル単位で分散して処理するパターンです。対象のバケットと、読み取り対象のパスを指定します。
CDKの場合は以下です。
itemReader: new sfn.S3ObjectsItemReader({ bucket: multiFileDataBucket, // バケットを指定 prefix: "csv/by_station/noah" // inputファイルが置いてあるファイルを指定 }),
ASLの場合は以下です。
"ItemReader": {
"Resource": "arn:aws:states:::s3:listObjectsV2",
"Parameters": {
"Bucket": "BUCKET_NAME",
"Prefix": "csv/by_station/noah"
}
},
パターン2. JSON / CSV / S3 Inventory
単一ファイルをインプットし、1ファイル内のレコード単位でMapに分散して処理するパターンです。対象のバケットと、対象のオブジェクトを指定します。
なおパラメータの maxItems は後続の処理に渡すレコード数を制限します。例えば 100 を指定すると、先頭100レコードのみ後続の処理に渡され、残りのレコードは一切処理されません(どういう時に使う想定なのかいまいちわかってないが、、、)。
CDKの場合は以下です。なお例は CSV ですが、JSONなど他のケースの場合でも設定内容はほぼ同一です。
itemReader: new sfn.S3CsvItemReader({ bucket: multiFileDataBucket, // バケットを指定 key: "object", // オブジェクトを指定 // maxItems: 100, // 処理するレコード数を絞りたい場合 // csvHeaders: sfn.CsvHeaders.use(['column1', 'column2']) // CSVファイルにヘッダーが存在せず、自分で定義したい場合は設定。 }),
ASLの場合は以下です。
"ItemReader": {
"Resource": "arn:aws:states:::s3:getObject",
"ReaderConfig": {
"InputType": "CSV",
"CSVHeaderLocation": "FIRST_ROW"
},
"Parameters": {
"Bucket": "BUCKET_NAME",
"Key": "KEY"
}
2. ItemSelector
後続のMapに渡す項目をフィルタするフィールドです。
例えば今回の題材だと、後続のMapの入力は以下が渡ってきます(CSVの全カラム)
{
"Items": [
{
"Etag": "\"c07d39a0b3c5df3f4cc4e6ca4c45a936\"",
"Key": "csv/by_station/noah/ASN00002059.csv",
"LastModified": 1710418636,
"Size": 14148,
"StorageClass": "STANDARD"
}
]
}
しかし今回 Map で動作する Lambda はKey のみしか使っていないため、他の項目は不要です。そのような時に ItemSelector を使うと Map に渡す項目の絞り込みができます。
これは JSONPathで "<新しいキー>.$": "$$.Map.Item.Value.<渡したい項目名>" と記載すれば良いです。$$ではなく$`としてしまうと正常に動作しないので注意してください。
今回は Key だけをキー名を変えずに渡したいので `"Key.$": "$$.Map.Item.Value.Key" のように設定します。
CDKの場合は以下です。
itemSelector: { "Key": sfn.JsonPath.stringAt('$$.Map.Item.Value.Key') },
ASLの場合は以下です。
"ItemSelector": {
"Key.$": "$$.Map.Item.Value.Key"
},
3. ItemBatcher と MaxConcurrency
ItemBatcher は Map に渡すデータ数(バッチサイズ)を決定します。またMaxConcurrencyは最大並列数を定義するパターメータであり、密に関係するためここでまとめて整理します。
まず ItemBatcher では以下2つを定義できます。両方指定した場合は制限が厳しい方に沿う形となります。
- MaxItemsPerBatch: Mapに渡す最大のデータ数を定義
- MaxInputBytesPerBatch:Mapに渡す最大のデータサイズを定義(最大256kb。未定義の場合も同様)
MaxConcurrency は 並列数の上限を定義します。MaxItemsPerBatchなどの設定から上限を超えそうになった場合にのみ機能します。
CDKの場合は以下です。
itemBatcher: new sfn.ItemBatcher({ maxItemsPerBatch: 100, maxInputBytesPerBatch: 262144, }), maxConcurrency: 1000,
ASLの場合は以下です。
"ItemBatcher": {
"MaxItemsPerBatch": 100,
"MaxInputBytesPerBatch": 262144
},
"MaxConcurrency": 1000,
なおそれぞれの項目で末尾に Path がついているものがあります。これを用いるとステートの入力に応じて動的に設定値を変えることが可能です。同一項目のPathなしとPathありは共存できません(例えばMaxConcurrencyとMaxConcurrencyPathは共存できない)。
CDKの場合は以下です。
// 動的に変更したい場合 itemBatcher: new sfn.ItemBatcher({ maxItemsPerBatchPath: sfn.JsonPath.stringAt('$.maxItemsPerBatch'), maxInputBytesPerBatchPath: sfn.JsonPath.stringAt('$.maxInputBytesPerBatch') }), maxConcurrencyPath: sfn.JsonPath.stringAt('$.maxConcurrency'),
ASLの場合は以下です。
"ItemBatcher": {
"MaxItemsPerBatchPath": "$.maxItemsPerBatch",
"MaxInputBytesPerBatchPath": "$.maxInputBytesPerBatch"
},
"MaxConcurrencyPath": "$.maxConcurrency",
上記で実装した場合は、ステートマシンで以下を入力として与えれば動的に並列数を制御が可能です。もちろん全項目を動的にする必要はなく、MaxConcurrency のみ動的にするなども可能です。
{
"maxConcurrency": 200,
"maxItemsPerBatch": 200,
"maxInputBytesPerBatch": 256,
}
4. ItemProcessor (Map)
分散処理の内容と定義するフィールド(子ワークフローを実装)です。
子ワークフローのタイプ(STANDARD, EXPRESS)を設定し、子ワークフローのStateを定義するのみです。ここは通常のステートマシンと大差ありません。
CDKの場合は以下です。
DistributedMap でタイプを定義 → 子ワークフローのStateを定義 → StateをItemProcessorに設定 の流れです。
// Distributed Map を定義 const distributedMap = new sfn.DistributedMap(this, 'MultiFileDistributedMap', { // 中略 mapExecutionType: sfn.StateMachineType.EXPRESS, // STANDARD or EXPRESS を選択。デフォルトは STANDARD // 以下略 }) // Lambda関数を呼び出すステートを定義(通常のワークフロー定義と同じ) const highPrecipitationFunctionTask = new tasks.LambdaInvoke(this, 'HighPrecipitationFunctionTask', { lambdaFunction: highPrecipitationFunction, payload: sfn.TaskInput.fromJsonPathAt('$'), outputPath: sfn.JsonPath.stringAt('$.Payload'), retryOnServiceExceptions: false }) // DistributedMapにItemProcessorを設定 distributedMap.itemProcessor(highPrecipitationFunctionTask, { })
ASLの場合は以下です。
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "DISTRIBUTED",
"ExecutionType": "EXPRESS"
},
"StartAt": "HighPrecipitationFunctionTask",
"States": {
"HighPrecipitationFunctionTask": {
"End": true,
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
],
"IntervalSeconds": 2,
"MaxAttempts": 6,
"BackoffRate": 2
}
],
"Type": "Task",
"OutputPath": "$.Payload",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "FUNCTION_NAME",
"Payload.$": "$"
}
}
}
},
5. ResultSelector
分散処理の結果ファイルをS3に書き込みます。実装はシンプルで出力対象のバケットと、出力オブジェクトのプレフィックス(パス)を指定するのみです。
CDKの場合は以下です。
resultWriter: new sfn.ResultWriter({ bucket: multiFileResultsBucket, prefix: "results" }),
ASLの場合は以下です。
"ResultWriter": {
"Resource": "arn:aws:states:::s3:putObject",
"Parameters": {
"Bucket": "BUCKET_NAME",
"Prefix": "results"
}
}
結果ファイルとしては2つ格納されます。
結果のメタデータ(manifest.json)
以下のように「書き込み先のバケット」、「出力対象となったMapの実行ARN」、「格納したオブジェクト(FAILED or PENDING or SUCCEEDED)」が記載されています。
{
"DestinationBucket": "書き込み先のバケット",
"MapRunArn": "MapRunのARN",
"ResultFiles": {
"FAILED": [],
"PENDING": [],
"SUCCEEDED": [
{
"Key": "results/21e936eb-c6f2-429c-b88d-7b0cdc509baf/SUCCEEDED_0.json",
"Size": 60778
}
]
}
}
結果データ
Map(子ワークフロー)の実行結果が書き込まれます。実行結果によってファイル名が変わります(FAILED or PENDING or SUCCEEDED)。
ファイルは長いので割愛しますが、子ワークフローの入力、出力などが全て出力されます。
6. ResultSelector
親ワークフローの出力項目をフィルターします。
例えばResultWriterで結果をS3に格納した後は以下のような結果が出力されます
{
"MapRunArn": "MapRunのARN",
"ResultWriterDetails": {
"Bucket": "BUCKET_NAME",
"Key": "results/9f44f1c3-412f-4f90-9350-5aeae5d3d333/manifest.json"
}
}
上記のうち項目を絞りたい場合に使います。以下はフィルタでバケット名のみ出力するようにした例です。
{
"result_bucket": "BUCKET_NAME"
}
実装方法は単純でJSONPathでフィルタするのみです。
CDKの場合は以下です。
resultSelector: { 'result_bucket': sfn.JsonPath.stringAt('$.ResultWriterDetails.Bucket') },
ASLの場合は以下です。
"ResultSelector": { "result_bucket.$": "$.ResultWriterDetails.Bucket" },
その他:エラーハンドリング
子ワークフローの失敗の許容値を定義できます。許容値を超えて失敗した場合は親ワークフロー全体を失敗扱いにします。
デフォルトだといずれも0のため、一つでも子ワークフローが失敗すると全体が失敗扱いになります。
ToleratedFailureCount:子ワークフローの失敗許容回数を定義(例:5個の子ワークフロー失敗までは許容する)toleratedFailurePercentage:子ワークフローの失敗許容割合を定義(例:全体の5%の子ワークフロー失敗までは許容する)
なおいずれもPathつきの項目も存在し、動的に設定することも可能です。
CDKの場合は以下です。
toleratedFailureCount: 5, toleratedFailurePercentage: 5,
ASLの場合は以下です。
"ToleratedFailurePercentage": 5,
"ToleratedFailureCount": 5,
なお末尾に Path 付きの設定項目も存在し、こちらを使用した場合は動的に許容値を変更可能です。
CDKの場合は以下です。
// 動的に変更したい場合 toleratedFailureCountPath: sfn.JsonPath.stringAt('$.toleratedFailureCount'), toleratedFailurePercentagePath: sfn.JsonPath.stringAt('$.toleratedFailurePercentage'),
ASLの場合は以下です。
"ToleratedFailurePercentagePath": "$.toleratedFailurePercentage",
"ToleratedFailureCountPath": "$.toleratedFailureCount",
なお親ワークフローが失敗した後に再実行(リドライブ)した場合は、失敗 or 未実行の子ワークフローのみ実行され、成功済みの子ワークフローは重複して実行されないような仕組みとなっています。
Distributed Mapのエラーハンドリングは以下の公式記事も参考になります。
並列数におけるコストの考慮
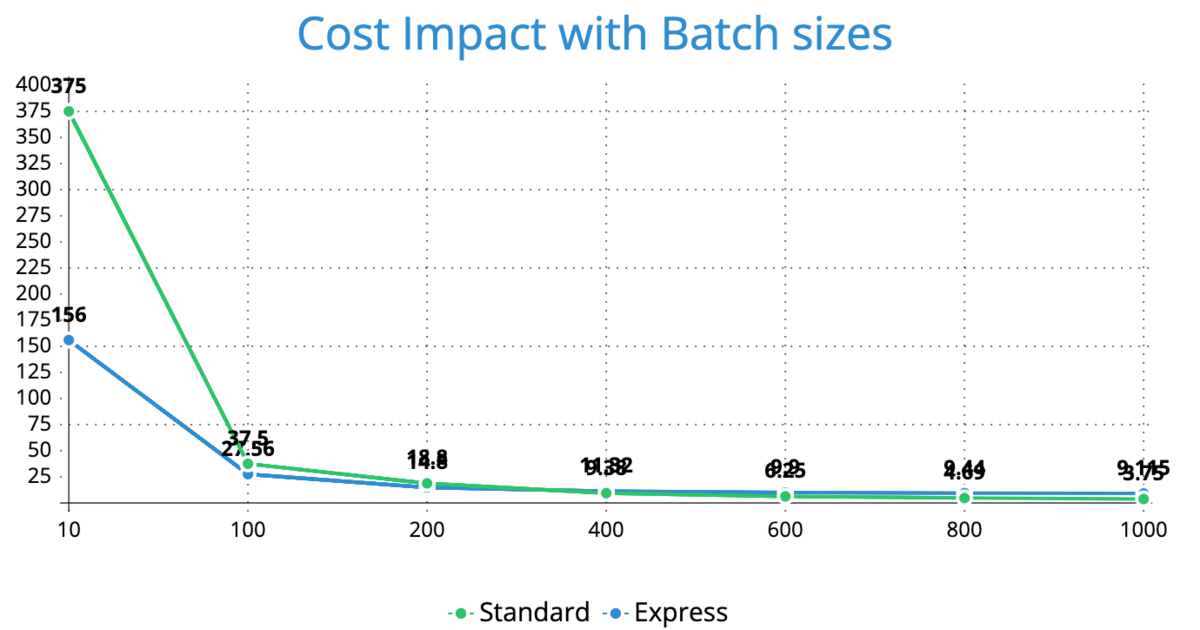
3. ItemBatcher と MaxConcurrency の設定が並列数を左右し、ひいては全体の処理時間を左右します。処理時間をなるべく短くするためには、可能な限りバッチサイズを小さくし並列数を増やすことが望ましいです。
しかしコストの考慮が必要になります。Step Functionsは状態遷移の数で課金額が増えるため、並列数をあげて子ワークフローを増やすと状態遷移も増え、結果的に課金額が増えていきます。
以下は公式のワークショップのグラフです。バッチサイズが小さいと課金額が高い傾向にあります。またバッチサイズが小さいとSTANDARD or EXPRESSの違いも大きくなります。
課金額も考慮して最適なバッチサイズを決める必要があります。
終わりに
設定項目が多くて大変ですが、使いこなすと非常に効果が大きい機能なので今後も活用していきたいです。