以下の記事においてAWS CDKでAurora グローバルデータベースをCDKで構築する方法、また運用が行えるかの解説を行なっていました。
記事内では「計画外フェイルオーバー」時のクラスターの切り離し作業等を行った際に、AWS CDKによる変更適用・その後の運用が行えるか検証しています。
一方でAWSのアップデートで「計画外フェイルオーバー」時もクラスターの切り離し作業等が不要となりました。
本記事ではこのアップデートに伴い、「計画外フェイルオーバー」発動後のCDKによる変更適用・その後の運用がどうなるかを検証・解説します。
結論としては以下の通りで、このアップデートによりCDKも踏まえた運用がかなり楽になりました。
※補足:AWSのアップデートに伴い以下のように用語が変化しています。
- スイッチオーバー(旧:計画内フェイルオーバー):PrimaryクラスターとSecondaryクラスターを入れ替えるだけのフェイルオーバー。運用メンテナンスなど、計画した上で行うもの。
- フェイルオーバー(旧:計画外フェイルオーバー):Secondaryクラスターを昇格させるフェイルオーバー。災害でPrimaryクラスターが使えなくなった場合などに行うもの。
目次
実装
以下にあります。前回の記事とほぼ同様ですが、一部実装方法を変えています。
東京リージョン(プライマリ)-大阪リージョン(セカンダリ)のAuroraグローバルデータベースを構築しています。
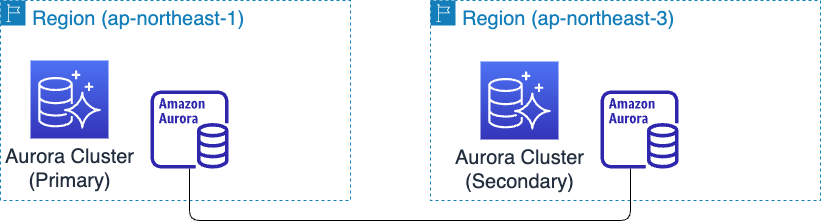
以下簡単に実装を解説します。
Appの実装
マルチリージョン構成のため、スタック分割が必須です。グローバルデータベースの識別子はAppからStackに渡すようにしました。
const globalClusterIdentifier = 'test-global-database' const app = new cdk.App(); // 東京リージョンのスタック new TokyoAuroraStack(app, 'TokyoAuroraStack', { env: { region: 'ap-northeast-1' }, globalClusterIdentifier: globalClusterIdentifier }) // 大阪リージョンのスタック new OsakaAuroraStack(app, 'OsakaAuroraStack', { env: { region: 'ap-northeast-3' }, globalClusterIdentifier: globalClusterIdentifier })
Stackの実装(東京リージョン)
前回の記事から大きくは変わっていません。DBクラスターを作成した後に、グローバルデータベース(CFnGlobalCluster)を定義しています。
DatabaseClusterのAPIが前回記事からアップデートされているため、書き方が変わっています(InstancePropsはdepreciated)。今回はServerless V2にしてみました。
この辺りの書き方については以下の記事でも解説しています。
また今回CLIでフェイルオーバーを行いたいため、グローバルデータベースや、DBクラスターの識別子を取得できるよう Output しています。
// Primary Cluster const dbCluster = new rds.DatabaseCluster(this, 'DatabaseCluster', { engine: rds.DatabaseClusterEngine.auroraMysql({ version: rds.AuroraMysqlEngineVersion.VER_3_06_0 }), vpc: vpc, vpcSubnets: vpc.selectSubnets({ subnetType: ec2.SubnetType.PRIVATE_ISOLATED }), // Writerインスタンスを定義(前回記事から変わっているところ) writer: rds.ClusterInstance.serverlessV2('Writer', {}), readers: [], defaultDatabaseName: 'test', backup: { retention: cdk.Duration.days(1) }, storageEncrypted: false, removalPolicy: cdk.RemovalPolicy.DESTROY }) // Global Database const globalClusterIdentifier = new rds.CfnGlobalCluster(this, 'GlobalDatabase', { deletionProtection: false, globalClusterIdentifier: props.globalClusterIdentifier, sourceDbClusterIdentifier: dbCluster.clusterIdentifier }) // CLIで識別子を取得するためアウトプット new cdk.CfnOutput(this, 'GlobalClusterIdentifier', { value: globalClusterIdentifier.globalClusterIdentifier!, exportName: 'GlobalClusterIdentifier', key: 'GlobalClusterIdentifier' }); new cdk.CfnOutput(this, 'ClusterIdentifier', { value: dbCluster.clusterArn, exportName: 'ClusterIdentifier', key: 'ClusterIdentifier' });
Stackの実装(大阪リージョン)
こちらも前回記事から大きくは変わっていません。セカンダリのDBクラスター作成後に、グローバルデータベース周りの設定を行い、CLI実行用にクラスター識別子をOutputします。
// Secondary Cluster const dbCluster = new rds.DatabaseCluster(this, 'DatabaseCluster', { engine: rds.DatabaseClusterEngine.auroraMysql({ version: rds.AuroraMysqlEngineVersion.VER_3_06_0 }), vpc: vpc, vpcSubnets: vpc.selectSubnets({ subnetType: ec2.SubnetType.PRIVATE_ISOLATED }), writer: rds.ClusterInstance.serverlessV2('Writer', {}), readers: [], backup: { retention: cdk.Duration.days(1) }, storageEncrypted: false, removalPolicy: cdk.RemovalPolicy.DESTROY }) const cfnCluster = dbCluster.node.defaultChild as rds.CfnDBCluster; // グローバルデータベースを設定 cfnCluster.globalClusterIdentifier = props.globalClusterIdentifier // クレデンシャルはプライマリから引き継ぐため未設定とする cfnCluster.masterUsername = undefined cfnCluster.masterUserPassword = undefined // DBクラスター識別子をアウトプット new cdk.CfnOutput(this, 'ClusterIdentifier', { value: dbCluster.clusterArn, exportName: 'ClusterIdentifier', key: 'ClusterIdentifier' })
フェイルオーバー動作検証
フェイルオーバー(旧:計画外フェイルオーバー)を実行し、その後CDKによる設定変更が行えるかを検証します。
フェイルオーバー実施
以下のようにフェイルオーバーを行い、Primaryを大阪リージョンに切り替えます。その後CDK上で設定変更を行い、適用できるか検証します。
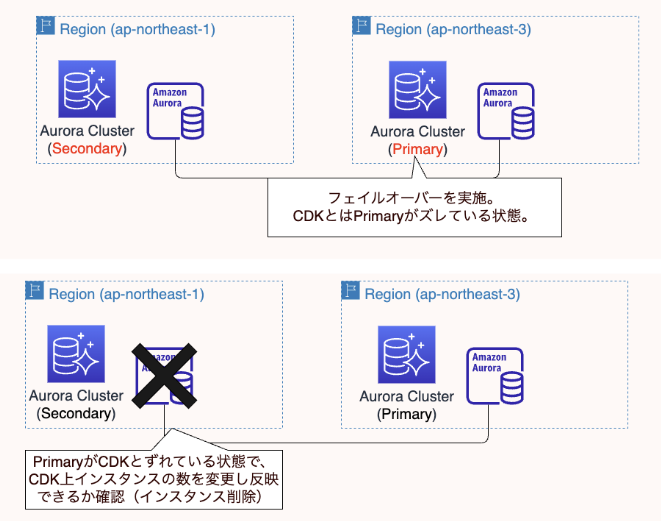
まずフェイルオーバーを実行します。今回はCLIで実行します。
# グローバルデータベースの識別子を取得 export GLOBAL_CLUSTER_IDENTIFIER=$(aws cloudformation describe-stacks --stack-name TokyoAuroraStack --output text --query 'Stacks[0].Outputs[?OutputKey == `GlobalClusterIdentifier`].OutputValue' --region ap-northeast-1) # 大阪リージョンのDBクラスターの識別子を取得 export SECONDARY_CLUSTER_IDENTIFIER=$(aws cloudformation describe-stacks --stack-name OsakaAuroraStack --output text --query 'Stacks[0].Outputs[?OutputKey == `ClusterIdentifier`].OutputValue' --region ap-northeast-3) # 大阪リージョンのDBクラスターにFailover aws rds failover-global-cluster --global-cluster-identifier $GLOBAL_CLUSTER_IDENTIFIER --target-db-cluster-identifier $SECONDARY_CLUSTER_IDENTIFIER
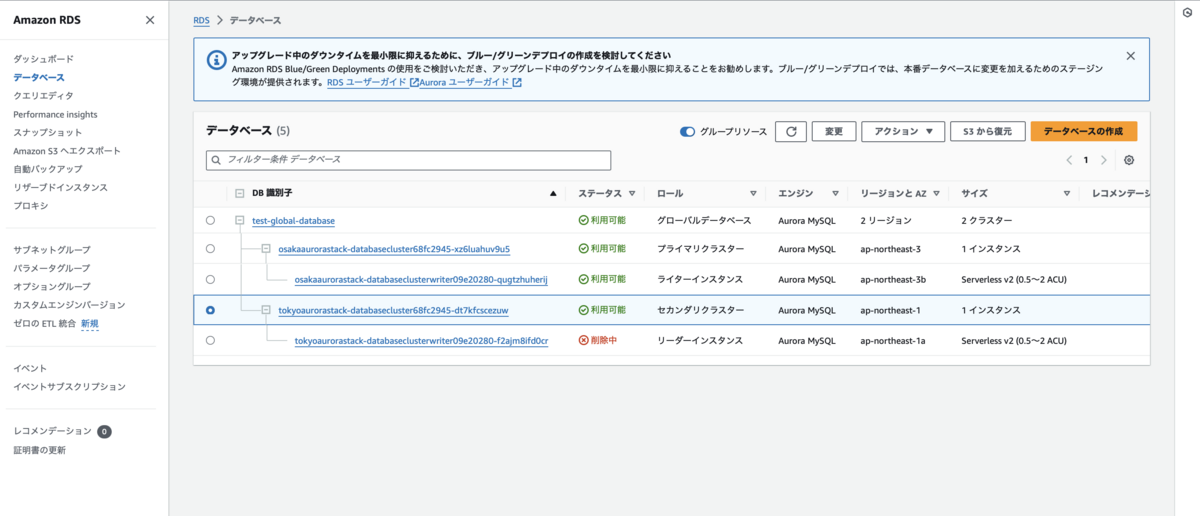
その後、東京リージョンのDBクラスターを0にする変更を適用します。ここはクラメソさんの以下の記事を参考にさせてもらいました。
// DBクラスターのインスタンスを削除 dbCluster.node.children.forEach((child) => { if (child.node.defaultChild instanceof cdk.aws_rds.CfnDBInstance) { dbCluster.node.tryRemoveChild(child.node.id); } })
この状態で cdk deploy を行うと以下のようにインスタンスが想定通り削除されました。問題なく変更適用ができるようです。
フェイルバック(再度フェイルオーバーを実施)
では再度フェイルオーバーを行い、東京リージョンのDBクラスターをプライマリに戻してみます。
以下のようにCLIを実行します。
# 東京リージョンのDBクラスター識別子を取得 export PRIMARY_CLUSTER_IDENTIFIER=$(aws cloudformation describe-stacks --stack-name TokyoAuroraStack --output text --query 'Stacks[0].Outputs[?OutputKey == `ClusterIdentifier`].OutputValue' --region ap-northeast-1) # 東京リージョンのDBクラスターにフェイルオーバー aws rds failover-global-cluster --global-cluster-identifier $GLOBAL_CLUSTER_IDENTIFIER --target-db-cluster-identifier $PRIMARY_CLUSTER_IDENTIFIER
すると以下のエラーになりました。
An error occurred (InvalidDBClusterStateFault) when calling the FailoverGlobalCluster operation: At least one active instance is required in the specified target DB cluster.
フェイルオーバー先はインスタンスが最低1台居ないとダメなようです(まあ考えてみれば当たり前かもですが)。
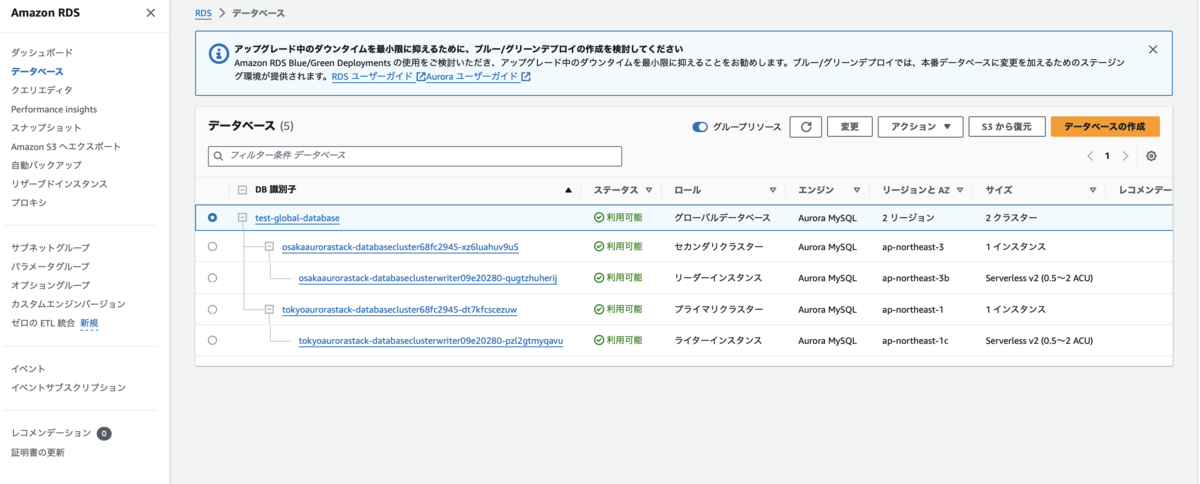
そのためこの後は、CDKの設定変更で東京リージョンのインスタンスを元の1台構成にし、フェイルオーバーを実行します(元に戻すだけなので手順は略)。
実行したら元に戻りました。当然ですが、この後CDKの変更適用も可能です。
まとめ
AWSのアップデートにより、Aurora グローバルデータベースのフェイルオーバー実行時はプライマリとセカンダリが入れ替わるのみとなりました。スイッチオーバーと大差ない挙動となり、結果的にCDKとの相性も良くなりました。
グローバルデータベースをCDKで取り扱う際のハードルが大幅に下がり、心理的な障壁も減ったのが非常に良いですね(前回記事で検証した内容は実践の機会がないままお蔵入り・・・笑)