はじめに
入門監視をはじめ一般的な監視に関するプラクティスは出回っているものの、AWSで具体的に何を監視するか?そのとっかかりについてはあまり出回っていないような気がします。
AWSの監視ってみんな何監視してるんすか…っていうぐらい実例あまり見つからないな。門外不出?
— mazyu36 (@mazyu36) 2023年2月14日
どこまで監視するかは基本的にシステムの特性によると思います。一方でAWSのサービスごとにシステムによらずよく監視で使う項目というのもあるかと思います。
今回は過去の経験をもとに、最低限この辺りは監視することが多いかなというものをまとめてみます。全体像としては以下になります。

最低限これは監視しないとダメでしょ、とかこれは不要でしょ、などなどあるかと思います。そういうのがあればぜひコメントいただきたいです。
- はじめに
- 「監視」について
- 前提
- 1-1. Webサービスの提供によく使うサービス群(フロント)
- 1-2. Webサービスの提供によく使うサービス群(バック)
- 1-3. Webサービスの提供によく使うサービス群(ストレージ)
- 2. ユーザーへの通知(SMS・メール配信)を行うためのサービス群
- 3. セキュリティに関するサービス群
- 終わりに
「監視」について
監視を行う際の仕組みとして以下の2つを構築することが多いと思いますが、今回は前者の「アラート」を扱います。
- アラート:システムにおいて何かしら対処が必要になった際に通知する仕組み。システムが正常に動作していないこと、もしくは問題が発生する予兆を検知してメール等で通知する。
- ダッシュボード:システムにおけるメトリクスを可視化する。運用の中で確認したり、アラート発生時に関連するメトリクスを確認したり等に使用する。
またアラートで使用するメトリクスに関しては、Googleの定義するGolden Signalに合致することが多いです。考える際の参考になるかと思います。
- Latency:処理時間。
- 処理に時間がかかっている場合は、「予兆」として検知することが可能かと思います。
- Traffic:リクエスト量。
- Errors:発生しているエラー。5xxエラー等は典型例。
- システムが正常に動作していないことを示すので、これは基本的にアラートの対象とすることが多いと思います。
- Saturation:リソース(CPU、メモリ等)の使用状態。日本語だと「飽和度」と訳されることもあります。
- CPUが大量に使用されている等の場合は、「予兆」として検知することが可能かと思います。
- ただしこれもアラートの対象外とすることは多いと思います。例えばCPUの使用率が90%を超えていたとしても、正常にサービスが提供できていれば問題ないという考え方。
- 個人的にはですが、AutoScalingの動作確認やインスタンスタイプが適切なのかの判断のために監視対象とすることが多いです。
※「アラート」や「ダッシュボード」という用語、Golden SignalsはSRE本 6章を参考にしています。英語版は以下で読めます。
前提
仕組みとしてCloudWatchを使用したオーソドックスなものを使用します。パターンとしては以下の2つになります。
- 各サービスから収集したメトリクスを元にアラートを行う。
- アプリから出力したログを元にアラートを行う。

監視対象のAWSサービスとしては、個人的によく使うサービスや、監視で特に注意を払ったことがあるサービスを取り上げます。
- Webサービスの提供によく使うサービス群
- ユーザーへの通知(SMS・メール配信)を行うためのサービス群:SNS, SES
- セキュリティに関するサービス群:CloudTrail, Config, Security Hub, GuardDuty
以下、カテゴリやサービスごとに、監視するメトリクスや項目の内容、考慮する点、公式の参考リンクを記載していきます。
1-1. Webサービスの提供によく使うサービス群(フロント)
Webサービスを提供する際に、ユーザーからのリクエストを受け付けるAWSサービス群になります。

(1). Application Load Balancer
【監視内容】
| メトリクス名 | 単位 | 説明 |
|---|---|---|
| TargetResponseTime | Seconds | リクエストがロードバランサーから送信され、ターゲットからの応答を受信するまでの時間。 |
| HTTPCode_ELB_5XX_Count | Count | ALBで生成された5xxエラーの数 |
| HTTPCode_Target_5XX_Count | Count | ターゲットで生成された5xxエラーの数 |
| TargetConnectionErrorCount | Count | ロードバランサーとターゲット間で正常に確立されなかった接続数。 |
| HealthyHostCount | Count | 正常とみなされたターゲットの数。 |
| UnHealthyHostCount | Count | 異常とみなされたターゲットの数。 |
TargetResponseTImeをもとにLatencyを監視します。平均はよく使います。また平均のみだとスパイクした時を検知できない可能性があるので、検知したい場合はパーセンタイルも使用した方が良いです。
HTTPCode_ELB_5XX_CountとHTTPCode_Target_5XX_Countで5xxエラーの監視をし、サービス提供に影響が出ていないかを確認します。違いとしてはELBで返却しているか or ターゲットで返却しているか、ですが、ELB_5xxだとしてもターゲットの異常の可能性もあるので注意が必要です。
なお、ELB_5xxは502などステータスコード別のメトリクスはありますが、Target_5XXはステータスコード別のメトリクスはありません。後者をステータスコード別に見たい場合はアプリケーションログに出力して集計するなどが必要です。
<参考>
TargetConnectionErrorCountもサービス提供に影響があるのでアラートの対象とすることが多いです。
HealthyHostCount、UnhealtyHostCountはターゲット(サーバー)の状態を監視するために対象にすることが多いです。前者はターゲットの数が必要最低数を下回った場合にアラートとする、後者は発生した場合に原因を調査するために1つでも発生したらアラートにする、とやることが多いです。
【検討事項】
ゴールデンシグナルのTrafficに相当するものを見たい場合は以下あたりを確認するのが良いかと思います。
ActiveConnectionCountRequestCountProcessedBytes
4xxエラーについてはダッシュボードで見ることはあるものの、アラートの対象とはしないことが多いです(ユーザーのリクエスト不正起因のことが多いため)。特性次第では対象としても良いかと思います。
【公式のリンク】
Application Load Balancer の CloudWatch メトリクス - Elastic Load Balancing
(2). Amazon CloudFront
【監視内容】
| メトリクス名 | 単位 | 説明 |
|---|---|---|
| OriginLatency | Milliseconds | CloudFrontがリクエストを受け付けてから、レスポンスを返すまでにかかった時間。 |
| 5xxErrorRate | Percent | 5xxエラーの割合。ALBやAPI Gatewayと違い、CloudFrontはPercentなので閾値設定時は注意。 |
Latency と Error に関わるメトリクスを監視しています。
LatencyとしてはOriginLatencyを監視しています。
Errorに関しては5xxエラーをまとめて監視することが多いです。502ErrorRateなどのステータスコード別の値はダッシュボードのみとし、アラートはまとめてとすることが比較的多い印象です。
【検討事項】
4xxエラーについてはダッシュボードで見ることはあるものの、アラートの対象とはしないことが多いです(ユーザーのリクエスト不正起因のことが多いため)。特性次第では対象としても良いかと思います。
またキャッシュ設定が適切に行えるかを見るために、キャッシュヒット(CacheHitRate)はダッシュボードに設定することが多いです。
【公式のリンク】
CloudWatch API を使用したメトリクスの取得 - Amazon CloudFront
(3). Amazon API Gateway
【監視内容】
| メトリクス名 | 単位 | 説明 |
|---|---|---|
| Latency | Milliseconds | API Gatewayがリクエストを受け付けてから、レスポンスを返すまでにかかった時間。 |
| 5XXError | Count | 5xxエラーの数 |
CloudFrontと同様にLatencyと5XXエラーに関するメトリクスを監視します。
API Gatewayに関しては5XXのメトリクスしかなく、502などステータスコード別に詳細を取ることはできません。
【検討事項】
4XXエラーやキャッシュヒットに関してはCloudFrontと同様にダッシュボードに設定することが多いです。
またLatencyとしてはIntegrationLatencyを用いると、API Gatewayからバックエンドにリクエストを中継し、バックエンドからレスポンスを受信するまでの時間が取得できます。
エンドユーザー視点だとトータルな値を示すLatencyをアラート対象とすることが多い印象ですが、要件によってはこちらもアラート対象にする、もしくはダッシュボードに設定しておくということを行なっても良いと思います。
【公式のリンク】
Amazon API Gateway のディメンションとメトリクス - Amazon API Gateway
(4). AWS WAF
【監視内容】
| メトリクス名 | 単位 | 説明 |
|---|---|---|
| BlockedRequests | Count | WAFによってブロックされた通信の数 |
WAFは監視対象としないことも多いです。
予期せぬブロックをプロアクティブに検知したい場合もあるため、上記メトリクスを監視することはあります。ただし、IP総当たりでの攻撃等は常に来るため、一律監視対象とすると必要以上にアラートが行われてしまいます。
監視する場合は特定のルールに限定するといった考慮が必要になります。
【検討事項】
個人的には特にないです。
【公式のリンク】
Amazon CloudWatch によるモニタリング - AWS WAF、AWS Firewall Manager、および AWS Shield Advanced
1-2. Webサービスの提供によく使うサービス群(バック)
リクエストをもとに業務処理を行うコンピュートサービス群です。
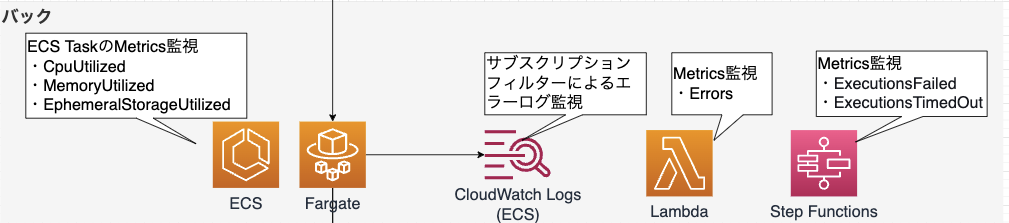
(1). Amazon ECS (on Fargate)
【監視内容】
ECSはメトリクスとエラーログ監視を行うことが多いです。
■メトリクス監視
メトリクスはいずれも Container Insightsで取得できるものです。
| メトリクス名 | 単位 | 説明 |
|---|---|---|
| CpuUtilized | Percent | タスクで使用されているCPUユニットの割合。 |
| MemoryUtilized | Percent | タスクで使用されているメモリの割合。 |
| EphemeralStorageUtilized | GiB | エフェメラルストレージで使用されたバイト数。 |
いずれもゴールデンシグナルのSaturationに該当するかと思います。
CpuUtilized, MemoryUtilizedはAutoScalingが適切に行われているかの監視として使用することが多いです。ターゲット追跡ポリシーのAutoScalingを設定した状態でCpuUtilizedが95%を超過する場合、AutoScalingの最大数が不足している、リクエストが偏っている等が考えられます。そのため調査のトリガーとしてアラート対象としています。一時的に閾値を超えたけどサービス提供に問題がないケースは対応しなくても良いかと思います。
EphemeralStorageUtilizedは2022/11から取得可能になった比較的新しいメトリクスです。アプリの特性としてエフェメラルストレージを多く使用する場合は監視対象とすることを検討した方が良いかと思います。
■エラーログ監視
アプリから出力したCloudWatch Logsのログに対してサブスクリプションフィルターで検知し、メールで通知するというのはよくやります。
やり方としてはログレベル(ERROR, CRITICAL等)の内、どのレベルだったらアラート対象とするかを事前に実装方針として決めておき、それに応じてアラートを出すというのがあります。
この場合、開発を始める前もしくは初期に方針を合わせておかないと大量にアラートが発生してしまうなどが起こりかねないので注意が必要かと思います。
認識がずれているとERRORでアラートとしたものの、ユーザーの入力値不正(設計の範囲内での準正常系)の場合もERRORで出力されるため、大量にアラートが行われてしまう等の事態になりかねません。
【検討事項】
タスクの数もアラート対象とするかは検討することが多いです。
ALB-ECSという構成の場合、ターゲットのメトリクスと重複するので省くことも多いです。一方、バックエンドで動いている、ALBにつながっていないマイクロサービスのタスクの数が正常に稼働しているかを監視しておきたい場合は、RunningTaskCountを監視することがあります。
【公式のリンク】
Amazon ECS Container Insights メトリクス - Amazon CloudWatch
(2). AWS Lambda
【監視内容】
| メトリクス名 | 単位 | 説明 |
|---|---|---|
| Errors | Count | Lambda実行時のエラーの数 |
実行失敗時はサービス提供に影響があるため、Errorsで監視します。なおタイムアウト時もErrorsとなるため、Latencyに関してはLambdaのタイムアウト時間で調整することが多いです。
【検討事項】
構成(SQSを使う場合等)によってはDeadLetterErrors, DestinationDeliveryFailuresを監視対象とすることはあります。
【公式のリンク】
Lambda 関数のメトリクスの使用 - AWS Lambda
(3). AWS Step Functions
【監視内容】
| メトリクス名 | 単位 | 説明 |
|---|---|---|
| ExecutionsFailed | Count | 失敗した実行の数。 |
| ExecutionsTimedOut | Count | タイムアウトした実行の数。 |
ステートマシンの実行失敗を検知するため、上記2つのメトリクスを監視します。
タイムアウトに関してですが、一定時間内に処理が終わる必要があることが多いため、ステートマシンにタイムアウト設定を行い、監視対象とすることが多いです。
ただしタイムアウトだと処理を強制的に打ち切ってしまうので、処理を打ち切らずに想定外に時間がかかっていることを検知したい場合はExecutionTimeを用いるのが一案です。
【検討事項】
アクティビティ単位で監視したい要件がある場合は、それ用のメトリクスを使用するのが良いかと思います。
【公式のリンク】
Step Functions のモニタリング CloudWatch - AWS Step Functions
1-3. Webサービスの提供によく使うサービス群(ストレージ)
キャッシュや永続化データを保存するサービス群です。

(1). Amazon ElastiCache(Redis)
【監視内容】
| メトリクス名 | 単位 | 説明 |
|---|---|---|
| CPUUtilization | Percent | CPUの使用率。 |
| Evictions | Count | メモリ溢れによりキー削除が発生した数。 |
| CurrConnections | Count | リードレプリカからの接続を除く、クライアント接続の数。 |
CPUUtilizationはインスタンスタイプが適切か、AutoScalingが適切に動作しているかを確認するために設定することが多いです。
EvictionsはElastiCacheはメモリ溢れを示すもので、ElastiCacheのメトリクスとしては最も重要なものの1つかと思います。これが頻繁に発生する場合はTTL等キャッシュ戦略を見直す必要があります。
なおEvictionについては設定内容次第ではメモリが解放されず、OutOfMemoryとなる可能性もあるので注意が必要です。
CurrConnectionsは接続数の監視のために設定します。接続数が異常に多い場合はコネクションが適切に閉じられていない等、アプリの実装に問題がある可能性があります。また最大接続数は65000となっているので、それに抵触しないように注意が必要です。
【検討事項】
公式のリンクに監視すべきメトリクスが掲載されているので、上記以外にも要件に応じて必要なものは設定するのが良いかと思います。
またElastiCacheの性質(キャッシュとしての用途)を踏まえるとキャッシュヒット率も重要な指標です。アラート対象にすることは多くない印象ですが、ダッシュボードで見れるようにすると重宝するかと思います。
またレイテンシやネットワークに関するメトリクスは、ダッシュボードで見れるようにしておき、フロントのレイテンシのメトリクスで問題が起きた場合に確認するこということが多いです。
【公式のリンク】
CloudWatch メトリクスの使用状況のモニタリング - Amazon ElastiCache for Redis
(2). Amazon Aurora
【監視内容】
Aurora Serverless v2を使用する機会も増えてきたので、特有のメトリクスも記載しています。
| メトリクス名 | 単位 | 説明 |
|---|---|---|
| CPUUtilization | Percent | CPUの使用率。 |
| FreeableMemory | MegaBytes | 空きメモリの量。 |
| DatabaseConnections | Count | データベースの接続数。 |
| FreeLocalStorage ※Not Serverless | Bytes | ローカルストレージの空き容量。 |
| ServerlessDatabaseCapacity ※Serverless | Count | インスタンス単位のACUの値。 |
| ACUUtilization ※Serverless | Percent | 最大ACUに対する使用率 |
CPUUtilization, FreeableMemory はインスタンスタイプの選定、AutoScaling、Serveless v2のACU設定が適切であるかの確認のために監視します。
DatabaseConnectionsは接続数の監視のために設定します。インスタンスタイプごとに接続最大数のデフォルトは決まっているため、それをもとに設定し設定変更要否やスケールアップ要否の検討に使用します。
なおAurora Serverless v2 の場合、接続最大数のパラメータはACUによって自動的に調節されます。
<参考>
Amazon Aurora MySQL のパフォーマンスとスケーリングの管理 - Amazon Aurora
Amazon Aurora PostgreSQL の管理 - Amazon Aurora
FreeLocalStorageは非Serverlessの時に監視すべきメトリクスの1つかと思います。枯渇するとクエリが実行できなくなりシステムがダウンする可能性があります。検知が遅くなると手遅れになる可能性があるので、対処に要する時間を考慮して設定が必要です。
ServerlessDatabaseCapacityとACUUtilizationはServerless v2においてACUが足りているかの確認に使用します。頻繁にアラートが発生するようであれば、最大ACUの変更や非Servelessへの移行を考えた方が良い可能性があります。ACUUtilizationが上限に到達しつつも、CPUUtilization, FreeableMemoryとしてはまだ余裕がある場合は、必ずしも問題があるわけではないので、合わせ技で見ることが多いです。
【検討事項】
レイテンシやネットワークに関するメトリクスはダッシュボードに設定し、必要に応じて確認することが多いです(直接アラート対象とはしないことが多い)。
監視からは少しずれますが、レイテンシで問題が発生した場合などはクエリ単位に調査することが多いので、スロークエリログやPeformance Insightsについては基本有効化しておきたいところです。設定しないと使えないので注意が必要です。
※参考
またサブスクリプションフィルタを使用すればAuroraのエラーログをもとにアラートを出すことも可能ですが、実施しないことの方が多いです。Auroraでエラーになる場合はアプリ側でも基本的にエラーになるため、2重アラートになる可能性が高いです。
【公式のリンク】
Amazon Aurora の Amazon CloudWatch メトリクス - Amazon Aurora
Aurora Serverless v2 でのパフォーマンスとスケーリング - Amazon Aurora
2. ユーザーへの通知(SMS・メール配信)を行うためのサービス群
ここはSNSによるSMS配信、SESによるメール配信が該当します。

(1). Amazon SNS
【監視内容】
| メトリクス名 | 単位 | 説明 |
|---|---|---|
| SMSMonthToDateSpentUSD | USD | 今月の始めから今日までの SMS メッセージの送信料金。 |
SMSメッセージの配信を行なっている場合、月々の使用料金(SMSMonthToDateSpentUSD)の監視は必須かと思います。
使用料金が使用限度額を超過すると配信が行われなくなるため、サービス提供に影響が出てしまいます。
増枠を行う場合はAWSサポートへの申請・許可が必要になるため、リードタイムも考慮した上でアラーム発行の閾値を決定するのが良いかと思います。
なお単位としてはUSDなので、閾値も40USDなど具体的な金額で設定する必要があります。
【検討事項】
配信失敗率をチェックしたい場合は「失敗した数(NumberOfNotificationsFailed)」や「正常配信率(SMSSuccessRate)」を監視するのが良いかと思います。
【公式のリンク】
CloudWatch を使用した Amazon SNS のモニタリング - Amazon Simple Notification Service
(2). Amazon SES
【監視内容】
| メトリクス名 | 単位 | 説明 |
|---|---|---|
| Reputation.BounceRate | Percent | バウンス率を表す(受信サーバーに拒否された割合。宛先が存在しない等) |
| Reputation.ComplaintRate | Percent | 苦情率を表す(メールがスパムとみなされた割合) |
バウンス率、苦情率は一定割合を超えるとAWSのレビュー対象となり、Eメール送信機能が停止される可能性があります(不適切な利用として見なされる可能性あり)。
そのため、SESを使用している場合は監視必須かと思います。バウンス率や苦情率による監視の閾値の目安はAWS公式のknowlede-centerにも記載されています。値が上昇している場合は何かしら対策を打つ必要があるので、対策に時間かかりそうなどあれば、公式記載の閾値より下げるのもありかと思います。
Amazon SES では、返送率を 5% 未満に維持することをお勧めします。返送率が 10% を超えると、Amazon SES はアカウントの E メール送信機能を一時停止することがあります。返送率のしきい値は 0.05 (5%) に設定することをお勧めします。 Amazon SES では、苦情率を 0.1% 未満に維持することをお勧めします。苦情率が 0.5% を超えると、Amazon SES はアカウントの E メール送信機能を一時停止することがあります。苦情率のしきい値は 0.001 (0.1%) に設定することをお勧めします。
<出典>
Amazon SES で返送率または苦情率のしきい値に関する通知を設定する
なお、値が上昇している場合の対策としてはケースによるので、一概には言いづらいですが以下のような対処をすることが多いと思います。
- バウンス率:存在しない宛先へのメール配信を行なっている可能性があるので対応を検討。
- システム上、無効となったアドレスに送信してしまっているロジックが無いか。特に一斉送信の時にありがち。
- ユーザーのメールアドレス登録ミスが起因の場合は、何かしら登録ミスを防止する仕組みを設ける。例えば入力パターンで正しいメールアドレス形式でないものは登録できないようにする、メールアドレス入力欄を2つ設けて一致しているかチェックするなど。
- 苦情率:SESのベストプラクティスに沿った設定を行う。
<参考リンク>
【検討事項】
メールの作成に失敗していないか確認したい場合は「レンダリング失敗(Rendering Failure)」を監視するのも良いかと思います。
【公式のリンク】
CloudWatch から Amazon SES イベントデータの取得 - Amazon Simple Email Service
3. セキュリティに関するサービス群
アカウントのセキュリティに関するサービス群です。 基本的にEventに基づく監視を行います。
(個人的には)あまり悩むポイントがないのでさらっと紹介します。

(1). Amazon GuardDuty
【監視内容】
検出結果のEventにおけるSeverity(重要度)を元にアラートを行います。Severityは数値であり、値が高いほど重要度が高く以下のようになっています。
- HIGH:8.9~7.0
- MIDDLE:6.9~4.0
- LOW:3.9~1.0
このうちHIGHは必ず監視、MIDDLEは場合による(監視することの方が多い)、LOWはしないことの方が多い、という印象です。
【検討事項】
個人的には特にありません。
【公式のリンク】
Amazon GuardDuty の検出結果について - Amazon GuardDuty
(2). AWS Security Hub
【監視内容】
GuardDutyと似ていますが、検出結果のEventにおけるSeverity(重要度)を元にアラートを行います。
以下参考リンクからの抜粋になります。
・INFORMATIONAL – このカテゴリには、PASSED、WARNING、NOT AVAILABLE チェック、または機密データの ID が含まれる場合があります。
・LOW — 将来の侵害につながる可能性のある結果。例えば、このカテゴリには、脆弱性、設定の弱点、公開されたパスワードなどが含まれる場合があります。
・MEDIUM – 現在進行中の侵害を示していても、攻撃者が目標を達成した兆候が見られない結果。例えば、このカテゴリには、マルウェアアクティビティ、ハッキングアクティビティ、異常な動作の検出などが含まれます。
・HIGH または CRITICAL – 実際のデータ損失、漏洩、サービス拒否など、攻撃者が目標を達成したことを示す結果。
このうちHIGH, CRITICALは必ず監視、MIDDLEは場合による、LOW, INFORMATIONALは基本しない、という印象です。
【検討事項】
個人的には特にありません。
【公式のリンク】
必須属性 - AWS Security Hub 自動的に送信される結果の EventBridge ルールの設定 - AWS Security Hub
(3). AWS CloudTrail
【監視内容】
メトリクスフィルターによる不正なAPI Callの監視を行うことが多いです。 Blackbeltのスライドがよくまとまっており参考になります。

 https://d1.awsstatic.com/webinars/jp/pdf/services/20210119_AWSBlackbelt_CloudTrail.pdf
https://d1.awsstatic.com/webinars/jp/pdf/services/20210119_AWSBlackbelt_CloudTrail.pdf
どこまで行うかはシステム特性にもよるとは思いますが、以下は最低限監視することが多いです。
- Rootユーザーの操作:Rootユーザーは基本封印するため。
- IAMポリシーの操作:権限に関する変更は重大であることが多いため。
- CloudTrailの操作:ログ取得をオフにされたりしないかを監視するため。
- アクセスキーの操作:アクセスキーが漏洩すると重大なインシデントにつながりかねないため。
【検討事項】
操作の失敗(Unauthorizedなど)は監視対象とするかは考慮した方が良いかと思います。基本的に本番環境では権限を最小限に絞ることが多いため、普通に運用者がコンソールで作業している際も一部のメトリクスが権限不足でロードできなくて誤検知するというようなことが起こりえます。
アラートが鳴りすぎたら意味ないので、システム特性や作業環境に合わせて検討が必要です。
【公式のリンク】
AWS CloudTrail を使用した Amazon CloudWatch Events API コールのログ記録 - Amazon CloudWatch Events
(4). AWS Config
【監視内容】
リソースがConfigルールに非準拠の場合をEventで検知してアラートを出します。Configルールの数だけ設定可能なので、当然ですが様々な設定が可能です。
観測範囲ではセキュリティグループが全解放になっている、S3バケットがパブリック公開されている、といったあたりが設定されることが多い気がします。
【検討事項】
検知対象のConfigルールを何にするかの検討に尽きます。
【公式のリンク】
List of AWS Config Managed Rules - AWS Config
AWS Config を使用して非準拠の AWS リソースに関する通知を受け取る
終わりに
おまけとしてCDKで監視設定の実装方法について軽く触れようかと思いましたが、長くなりすぎたので別記事で記載します。
(2023/2/26追記)
CDKでの実装方法についても別記事で作成しました。