はじめに
あるプロジェクトでECS on Fargateで以下のFirelensによるログ管理サイドカーを行う必要性が出てきたので、CDKによる実装れいを記載する。
ログ管理サイドカー前々からやりたいと思ってたので、CDKでやってみるhttps://t.co/4xvdnIwHKe
— mazyu36 (@mazyu36) 2022年11月13日
※Firelensの詳細は以下を参照
導入
動機
ECS on FargateでFirelensによるログ管理サイドカーを導入したい動機としては以下があると思う。
- CW Logsのコストが高い:これが最も大きな理由かと思う(ここが許容できるのであれば導入しなくて良いと思う)。CW Logsに大量のログを転送および保管をするとかなりコストがかかる。そのため大量にログを出力するようなアプリの場合、最低限のログ(エラーログなど)はCW Logs、それ以外の全量はS3への保存などにした方が良い。
- ALBのヘルスチェックのログが鬱陶しい:ALBからのヘルスチェックのログが大量に出力される。無視すればいいのだが出力してもほぼ見ないため、削っても良いと思う。
実装の全体像
以下のようにFirelensによりログを以下の3つに分岐させるように実装してみた。
- CloudWatch Logs:重要度が高いログ(エラーログ)のみ転送。
- Firehose+S3:ヘルスチェック以外のログは全てS3に転送。Athenaでログ分析を行えるようGlueのデータベースおよびテーブルも作成する。
- ゴミ箱:ALBのヘルスチェックログはどこにも出力せず捨てる。
なおログを出力するサンプルアプリはPython(Flask)で作成している。

また実プロジェクトだと、1リポジトリから複数環境(dev, stg, prodなど)にデプロイすることも多いので、環境差分にも対応できる形で実装した。
ソース
実装全量は以下。
1. サンプルアプリ(Flask)の実装
Firelensの動作確認用アプリとしてFlaskを使用し、さまざまなログを出力する簡易アプリを実装した。
以下の5つのエンドポイントを用意している。
/info:INFOログを出力するためのエンドポイント/error:ERRORログを出力するためのエンドポイント/critical:CRITICALログを出力するためのエンドポイント/exception:Exceptionを発生させるためのエンドポイント。複数行ログの動作確認用に作成。/health:ヘルスチェック用のエンドポイント。ヘルスチェックログの動作確認用に作成。
エンドポイントの実装としては以下のように、エンドポイントにアクセスすると該当するログレベルでの出力だけを行うなど、簡易的なものである。
# CRITICALでログを出力する。INFOやERRORも同様の実装 @app.route('/critical') def hello_critical(): app.logger.critical("This is a Critical log") return "<p>Hello Critical</p>" # Exceptionを発生させる。ここでは0除算にしている @app.route('/exception') def hello_exception(): try: 1 / 0 except BaseException: app.logger.exception("Unexpected error occurred") return "<p>Hello Exception</p>" # ヘルスチェック用のエンドポイント。正常応答を返すのみ。 @app.route("/health") def health(): return jsonify({"status": "success"})
上記を元にコンテナイメージを作成してサンプルアプリとして動作させて検証を行なっている。
なおDockerfileについては「とりあえず動くもの」を作っており、ベストプラクティスには沿ってないので注意(非root化、命令の最適化などは一切やっていない。商用の場合は考慮する必要あり。)。
2. Firelensの実装
Firelensで自前でログ分岐等の設定を行うには以下の2つがある。ただし2023/1現在Fargateの場合は後者しか対応していない。
- S3に設定ファイルを配置しておいてコンテナ起動時に読み込み
- 設定ファイルを元にカスタムしたコンテナイメージを作成しておく
そのため自前でコンテナイメージを作成する必要がある(ここがちょい面倒...)
Dockerfile
以下のようにベースイメージを指定して、設定ファイルのコピーとタイムゾーン指定をやっているのみである。
FROM amazon/aws-for-fluent-bit:2.29.0 COPY ./extra.conf /fluent-bit/etc/extra.conf RUN ln -sf /usr/share/zoneinfo/Asia/Tokyo /etc/localtime
extra.conf
Firelens用の設定ファイルを作成している。 こちらは以下の記事を参考にさせていただいた。
以下上記の参考記事から変更している点のみ記載する。
■multiline ログへの対応
# pythonで複数行のログ(主にStackTrace)を結合するための設定 [FILTER] Name multiline Match * multiline.key_content log multiline.parser python
Filterで複数行のログを結合する設定をしている。これを行わないとスタックトレース(複数行のログ)が一行ごとに分割されて出力されてしまい、可読性が落ちる。
今回はビルトインのpythonのパーサーを使用している(goやJavaなどもあり)。
またパーサーを自作することも可能。詳細は以下を参照のこと。
■ヘルスチェックログの除外設定
[FILTER] Name grep Match *-firelens-* Exclude log ^(?=.*GET \/health HTTP\/1\.1).*$
今回のサンプルアプリでは以下のようなヘルスチェックログが出力されるため、こちらを除外する形としている。
\"GET /health HTTP/1.1\" 200 -
■エラーログをCW Logsに転送する設定
# ERROR/CRITICALログに対してerror-を付与するための設定 [FILTER] Name rewrite_tag Match *-firelens-* Rule $log (ERROR|CRITICAL) error-$container_id false # CloudWatch Logsへの出力設定 # ログ保持期間の設定やロググループの作成はCDK側で行うためコメントアウトしている。 [OUTPUT] Name cloudwatch_logs Match error-* region ${AWS_REGION} log_group_name ${LOG_GROUP_NAME} log_stream_prefix app-log- #log_key log #CW Logsには"log"のみ出力したい場合 #log_retention_days 1 #auto_create_group true
今回はERRORとCRITICALを転送する形としている。以下のように処理する設定としている(参考記事通り)。
FILTERで対象のログにerror-を付与する。OUTPUTでerror-が付与されている(Matchに該当)ログは転送対象とする。
またロググループ名は環境差分に対応するため環境変数としている。詳細はCDKの実装箇所で説明。
■Kinesis Firehose(+S3)にログを出力するための設定
# Kinesis Firehoseへの出力設定 # ログの出力時刻としてtimeを付与 [OUTPUT] Name kinesis_firehose Match * region ${AWS_REGION} delivery_stream ${FIREHOSE_STREAM_NAME} time_key time time_key_format '%Y-%m-%d %H:%M:%S'
ヘルスチェック以外のログをKineis Firehoseに転送する設定。
ロググループと同様にFirehoseの配信ストリーム名は環境差分に対応するため環境変数としている。
またS3にログを転送する際にログの出力時刻を付与するよう、time_keyとtime_key_formatを設定している。
3.AWS CDKの実装
ログ出力先のS3バケットおよびKinesis Firehoseの実装
以下の参考記事の実装を参考、というかほぼ丸ぱくりさせていただいた。
参考記事の内容を元にログの出力先バケットとそこに配信を行うKinesis Firehoseの配信ストリーム作成に加え、Firehoseへの配信失敗時のログ出力設定をしている。
※変更したのは各種名称設定や、バッファリングの設定ぐらい。
ECS周りの実装
Flask(アプリ側)の実装
簡略化のためecsPattern(L3 Construct)のApplicationLoadBalancedFargateServiceを使用(コンテナ関連のパラメータのみ指定すれば、ALBやVPCなども全て自動で作成してくれるもの)。
※L3 Constructは抽象度高すぎて本番環境等では使いにくいが、こういうサンプル実装の時は便利。
// 簡略化のためecsPatternsのものを使用 const loadBalancedFargateService = new ecsPatterns.ApplicationLoadBalancedFargateService(scope, 'Service', { memoryLimitMiB: 1024, desiredCount: 1, cpu: 512, taskImageOptions: { image: ecs.ContainerImage.fromEcrRepository(flaskRepository, "latest"), logDriver: ecs.LogDrivers.firelens({}), // LogDriverでfirelensを指定 containerPort: 5000 } }); // ヘルスチェックの設定 loadBalancedFargateService.targetGroup.configureHealthCheck({ path: '/health', }); // Flaskのエラーログを流すCW Logsのロググループ const ecsLogGroup = new logs.LogGroup(scope, 'FlaskLog', { logGroupName: `${props.prefix}-flask-log`, retention: logs.RetentionDays.ONE_DAY, removalPolicy: RemovalPolicy.DESTROY, });
以下ポイントを記載。
■ログドライバーの指定
アプリのコンテナのログドライバーでfirelensを指定する必要がある。
今回は特にパラメーターを指定していないが、必要に応じて設定する。
logDriver: ecs.LogDrivers.firelens({}), // LogDriverでfirelensを指定
■ロググループの作成
こちらはFirelensからの出力先である。
直接アプリ(Flask)のコンテナから出力するわけではないため、ECSサービスからは参照していない点に注意。
const ecsLogGroup = new logs.LogGroup(scope, 'FlaskLog', { logGroupName: `${props.prefix}-flask-log`, retention: logs.RetentionDays.ONE_DAY, removalPolicy: RemovalPolicy.DESTROY, });
Firelensに関する実装
今回の一番メインとなる箇所である。
まずFirelens自体のログを流すロググループを作成しておく。 Firelens自体のログ出力は必須ではないが、正常に動作しない場合等に確認するために基本的に出力しておいた方が良いと思う。
// Firelensのログを流すCW Logsのロググループ const firelensLogGroup = new logs.LogGroup(scope, 'FirelensLog', { retention: logs.RetentionDays.ONE_DAY, removalPolicy: RemovalPolicy.DESTROY, });
次にFirelensのコンテナをタスク定義に追加する。
追加する際はタスク定義に対してaddFirelensLogRouterを使用すれば良い。
実装例はL3 Constructを使用しているがL2 Constructでタスク定義を作成した場合なども同様である。
essential、ヘルスチェック、ロググループに関しては要件次第で設定すれば良い。
essential:Firelensコンテナだけ停止した場合にタスクを停止、再起動させるかどうかで決定(基本はtrueにした方が良い気がするけど)- ヘルスチェック:Firelensコンテナ自体のヘルスチェックの設定。なくてもいいけどあったほうがベターな気はする。
- ロググループ:Firelens自体のログ出力先の設定。ヘルスチェックのログも出力されず、少量なので基本は出力するでいい気はする。
以下が実装例。実装のポイントは後述する。
// タスク定義に対してFirelensのLogRouterを追加する。 loadBalancedFargateService.taskDefinition.addFirelensLogRouter('logRouter', { image: ecs.ContainerImage.fromEcrRepository(firelensRepository, "latest"), essential: true, // trueにするとFirelensコンテナが死んだ場合、タスク自体を終了させる動作となる。 healthCheck: { // Firelens自体のヘルスチェックの設定 command: ["CMD-SHELL", "echo '{\"health\": \"check\"}' | nc 127.0.0.1 8877 || exit 1"], interval: cdk.Duration.minutes(3), retries: 3, startPeriod: cdk.Duration.minutes(3), timeout: cdk.Duration.seconds(30), }, // Firelensのロググループを設定 logging: ecs.LogDrivers.awsLogs({ streamPrefix: 'firelens', logGroup: firelensLogGroup, }), // Firelensの設定ファイルの指定 firelensConfig: { type: ecs.FirelensLogRouterType.FLUENTBIT, options: { configFileType: ecs.FirelensConfigFileType.FILE, configFileValue: '/fluent-bit/etc/extra.conf', enableECSLogMetadata: true } }, // APログの出力先は環境依存のため、環境変数経由で渡す environment: { 'LOG_GROUP_NAME': ecsLogGroup.logGroupName, 'FIREHOSE_STREAM_NAME': props.firehoseStream.deliveryStreamName! }, })
■Firelensの設定ファイルの読み込み設定
カスタムイメージにおいて作成した設定ファイルを指定する。
種別としてFILE、ファイル名はDockerfileで指定したものを設定する。
// Firelensの設定ファイルの指定 firelensConfig: { type: ecs.FirelensLogRouterType.FLUENTBIT, options: { configFileType: ecs.FirelensConfigFileType.FILE, configFileValue: '/fluent-bit/etc/extra.conf', enableECSLogMetadata: true } },
■環境変数の設定
次のポイントは、Firelensからログを転送する「ロググループ名」と「Firehoseのストリーム名」を環境変数経由で渡す点である。
// APログの出力先は環境依存のため、環境変数経由で渡す environment: { 'LOG_GROUP_NAME': ecsLogGroup.logGroupName, 'FIREHOSE_STREAM_NAME': props.firehoseStream.deliveryStreamName! },
「ロググループ名」はFirelensの設定ファイル(extra.conf)で定義する形となる。
しかし設定ファイルにハードコーディングしてしまうと、複数環境に対してデプロイしたい場合にリソース名が競合してしまう。
そのため環境ごとに異なるリソース名を使い分けられるよう、Firelensコンテナの環境変数にリソース名を指定し、設定ファイルでは環境変数からログの転送先を読み込む形にすることで、実装を変更することなく複数環境にデプロイ可能となる。
以下がextra.confの該当箇所である。
[OUTPUT] Name cloudwatch Match error-* region ${AWS_REGION} log_group_name ${LOG_GROUP_NAME} # ロググループ名を環境変数で取得 log_stream_prefix app-log/ #log_retention_days 1 #auto_create_group true [OUTPUT] Name firehose Match ** region ${AWS_REGION} delivery_stream ${FIREHOSE_STREAM_NAME} # Firehoseのストリーム名を環境変数で取得 time_key time time_key_format '%Y-%m-%d %H:%M:%S.%L'
あとはタスクロールにCW LogsやKinesis Firehoseにログを転送するための権限を付与すれば良い。
Athena関連
以下のようにAthenaのクエリ結果を出力するためのS3バケット作成と、ワークグループ作成を行う。
これによりコンソール上からはワークグループを切り替えるだけでクエリを投げることが可能。
ついでにエンジンバージョンを執筆時点の最新版(v3)にしている。
// Athenaのクエリ結果を出力するためのバケット const athenaQueryResultBucket = new s3.Bucket(scope, 'AthenaQueryResultBucket', { removalPolicy: cdk.RemovalPolicy.DESTROY, autoDeleteObjects: true, accessControl: s3.BucketAccessControl.PRIVATE, blockPublicAccess: s3.BlockPublicAccess.BLOCK_ALL, encryption: s3.BucketEncryption.S3_MANAGED } ); // Athenaのワークグループを作成。エンジンバージョンは3を指定。 new athena.CfnWorkGroup(scope, 'AthenaWorkGroup', { name: `${props.prefix}-athenaWorkGroup`, workGroupConfiguration: { engineVersion: { selectedEngineVersion: 'Athena engine version 3', }, resultConfiguration: { outputLocation: `s3://${athenaQueryResultBucket.bucketName}/result-data`, }, }, recursiveDeleteOption: true, });
Glue関連
以下Glue Data Catalogのデータベースおよびテーブルを作成していく。
なお執筆時点ではGlueの正式なL2 Constructは無いためL1 Constructを使用して作成している。
// Glue データベースを作成 new glue.CfnDatabase(scope, 'GlueDatabase', { catalogId: accountId, databaseInput: { name: `${props.prefix}-log-database`, }, }); // Glue テーブルを作成 // Partition Projectionを使用(dateでパーティション化) new glue.CfnTable(scope, "GlueTable", { databaseName: `${props.prefix}-log-database`, // Glueデータベースの名称と一致させる catalogId: accountId, tableInput: { name: `${props.prefix}-flask-log`, tableType: "EXTERNAL_TABLE", parameters: { "projection.enabled": true, "projection.date.type": "date", "projection.date.range": "2023/01/01, NOW+9HOUR", "projection.date.format": "yyyy/MM/dd", "projection.date.interval": "1", "projection.date.interval.unit": "DAYS", "serialization.encoding": "utf-8", "storage.location.template": `s3://${props.logBucket.bucketName}/ecs-logs/` + "${date}", // ecs-logsはKinesis Firehoseで指定したprefixと一致させている }, storageDescriptor: { columns: [ { "name": "container_id", "type": "string" }, { "name": "container_name", "type": "string" }, { "name": "ecs_cluster", "type": "string" }, { "name": "ecs_task_arn", "type": "string" }, { "name": "ecs_task_definition", "type": "string" }, { "name": "log", "type": "string" }, { "name": "source", "type": "string" }, { "name": "time", "type": "string" } ], inputFormat: "org.apache.hadoop.mapred.TextInputFormat", outputFormat: "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat", serdeInfo: { serializationLibrary: "org.openx.data.jsonserde.JsonSerDe", }, location: `s3://${props.logBucket.bucketName}/ecs-logs`, }, partitionKeys: [ { "name": "date", "type": "string" }, ] } })
ポイントとして今回はPartition Projection(パーティション射影)を使用してパーティション管理を自動化している。
dateでパーティション化することでクエリ実行時の検索範囲を限定可能としている。
動作確認
ここまでの実装内容をもとにCDKでデプロイを行い、正しく動作するか試してみる。
①CDKのデプロイとログ出力
まず以下のようにprefixをcontextで指定してcdk deployを行う。
cdk deploy -c prefix=test
デプロイが完了したら、Flaskでエンドポイントを複数回叩いてログを出力する(/info, /error, /critical, /exceptionの4つ)。
※/healthはALBのヘルスチェック用なのでわざわざ叩く必要はない。
ブラウザで叩くと以下のようにpタグが表示されるのみ(裏ではログが出力されている)。


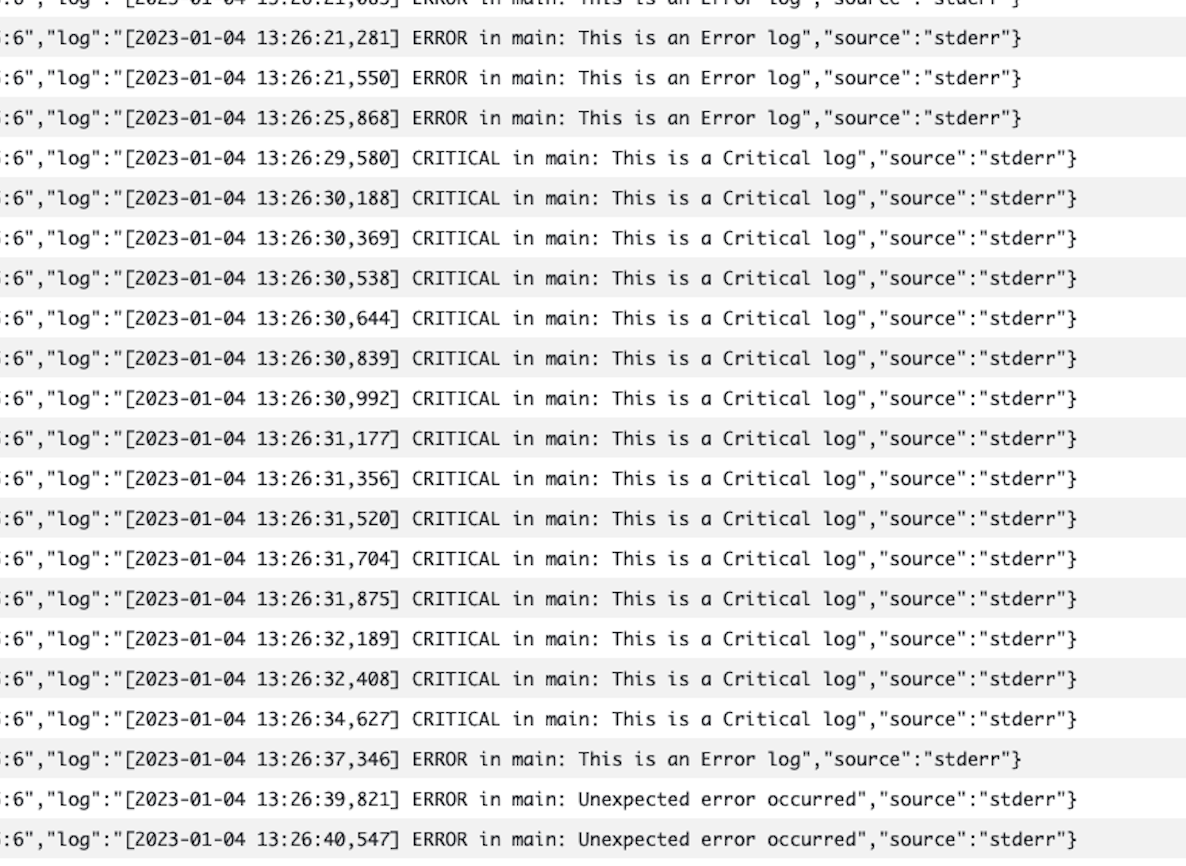
②CloudWatch Logsの出力内容確認
ロググループにエラーログ(ERRORとCRITICAL)のみが出力されていることを確認する。
マネコン上から覗くと以下のようにログが出力されている。

右にスクロールしてみるとERRORとCRITICALのみが出力されていることがわかる。これでCloudWatch Logsへの出力は問題ないことが確認できた。
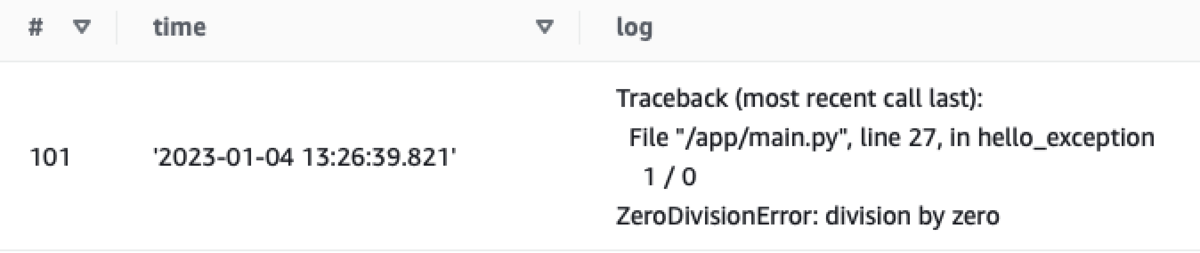
③S3への出力内容確認
Athenaでクエリをしてログの出力内容を確認してみる。ここで確認したい点は以下2つである。
- ヘルスチェックログ以外が出力されていること(ヘルスチェックログは出力されていないこと)
- スタックトレースが分割されていないこと(複数行ログが設定通り1レコードで出力されていること)
まずS3のログの内容を確認すると以下のように出力日時で階層化されている

次にAthenaにおいてCDKで作成したワークグループを設定する(画面右上)。

その上でdateで検索範囲を指定してクエリを投げるとログが取れる。ざっと眺めてみるとヘルスチェックのログは出力されていないことが確認できた。

スタックトレースについても想定通り分割されずに1レコードで出力されている。これでS3への出力も問題ないことが確認できた。
これで一通り動作確認完了である。
終わりに
一通りできたが、Fluentbit力を強化して改善していきたい。